

- Структура XML¶
- Сущности¶
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Составляем свой запрос
- Разбор xl/worksheets/sheet1. xml
- Well Formed XML
- Есть корневой элемент
- У каждого элемента есть закрывающийся тег
- Теги регистрозависимы
- Правильная вложенность элементов
- Атрибуты оформлены в кавычках
- Разбор xl/caclChain. xml
- Пространства имен
- Разбор docProps/app. xml
- Поиск информации в XML файлах (XPath)¶
- Разбор [Content_Types]. xml
- Завершение
- Удаление лишних блоков(абзацев) из XML по заданному условию¶
- Суть проблемы¶
- Решение проблемы¶
- Правила синтаксиса (Валидность)¶
- Обзор DOM3 XML
- Разбор xl/worksheets/_rels/sheet1. xml. rels
- Разбор xl/sharedStrings. xml
- Структура xml файла
- Комментарий
- Элементы
- Дерево элементов
- Работа с файлами отчетов Росстата¶
Структура XML¶
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите,
например, символ внутри XML элемента, то будет
сгенерирована ошибка, так как парсер интерпретирует его, как начало
нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении атрибута содержатся символы и .
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ на его
сущность. В XML существует 5 предопределенных сущностей:
Только символы и строго запрещены в XML. Символ допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
И разберемся, что означает эта запись.

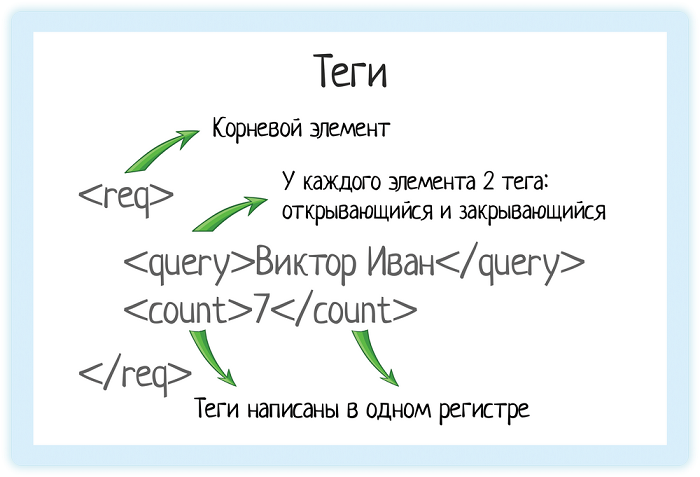
Теги
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
Текст внутри угловых скобок — название тега.
Тега всегда два:
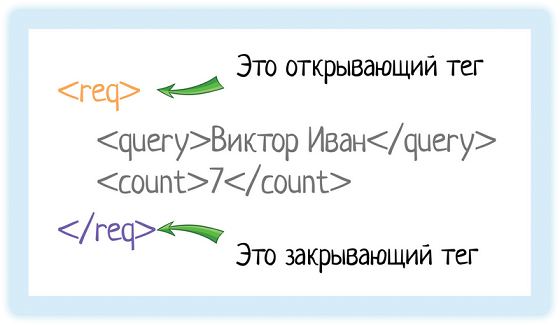
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое:
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!

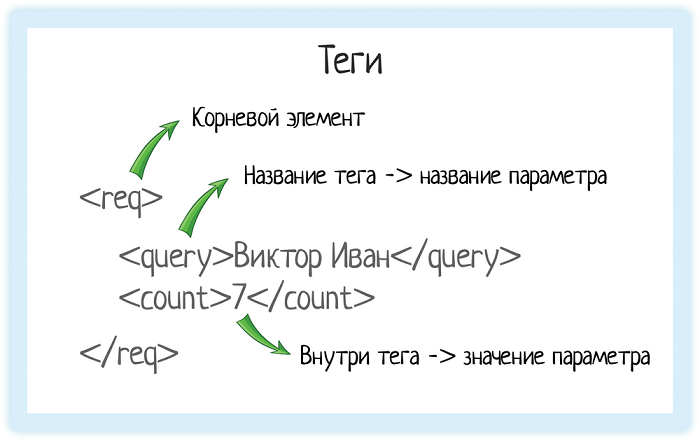
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».

Он мог бы называться по другому:
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
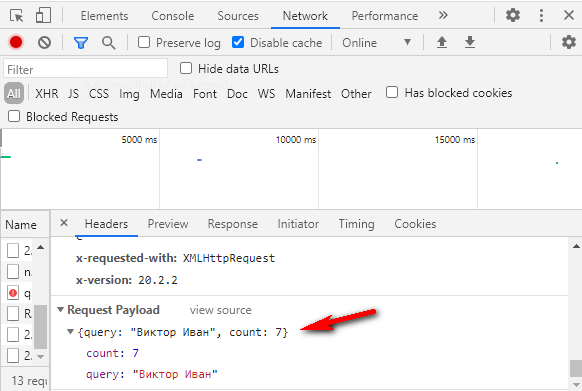
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.

Внутри — значение запроса.
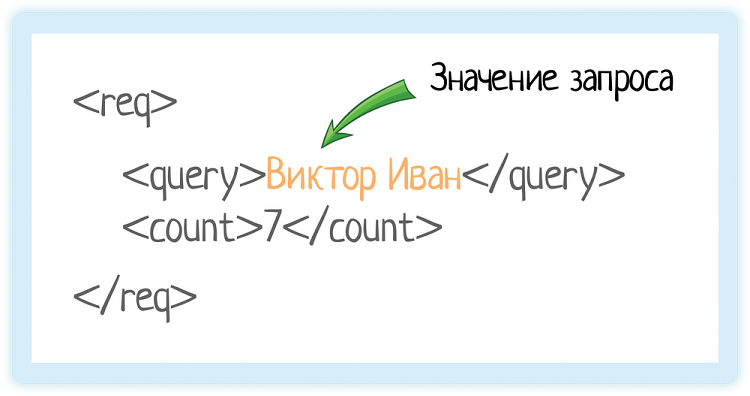
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Но оба значения идут
кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»

Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
Давайте разберем эту запись. У нас есть основной элемент party.

У него есть 3 атрибута:

Внутри party есть элементы field.

У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.

Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. Т З может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:

У элемента attribute есть атрибуты:

А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.

Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!

А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.

Итого, как используется схема при разработке SOAP API:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
А в WSDl сервиса она записана еще проще:
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!

Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. « Женский» по английски будет FEMALE, в документации также. Итого получили:
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Разбор xl/worksheets/sheet1. xml
Начинается самое интересное и большое в этой статье.
Начинается такой файл с обычного объявления типа документа xml и некоторых настроек:
Строка третья означает размер экспортируемого диапазона (с какой по какую ячейку находятся данные).
В теге sheetView — selection описывается выделенная клетка (или диапазон клеток).
Атрибут activeCell — активная ячейка, sqref — выделенная ячейка или диапазон ячеек.
такая строка может выглядеть и вот так:
Здесь уже вместо атрибута activeCell стоит activeCellId, потому что в атрибуте sqref мы видим несколько диапазонов. исходя из этого выясняем, что активный диапазон является A1:C3. на изображении ниже показано, как выглядит такой вариант выделения ячеек.
ySplit — показывает количество закрепленных строк. Для закрепления столбцов есть аналогичный атрибут xSplit;
topLeftCell — указание левой верхней ячейки, видимой по умолчанию НЕзакрепленной области;
activePane — указание местонахождения НЕзакрепленной области. В руководствах сказано, что этот атрибут регулирует, с какой стороны будет НЕзакрепленная область. Правда, попробовав разные значения, я почему-то получил одинаковый результат. Как вариант «by default» я для себя выбрал bottomRight;
state — указатель состояния закрепленной области. Для простого закрепления строки используется значение frozen
Интересен нам здесь в основном атрибут defaultRowHeight, то есть высота столбца по умолчанию. Стандартный, привычный нам вариант — 15 у.е. Если назначить его, скажем, 30 у.е., то строки, для которых высота не указана отдельно, станут в 2 раза выше. Однако, для того чтоб применить значение, отличное от дефолтного, необходимо указать атрибут customHeight со значением «true». Выглядит это примерно так:
Атрибут min — первый столбец группы;
Атрибут max — последний столбец группы;
Атрибут width — ширина столбца из группы;
Атрибут customWidth — флаг применения кастомной ширины, без него ширина все равно будет дефолтной;
Тег sheetData — описание содержимого ячеек и их настроек.
здесь структура такова:
В Excel это будет выглядеть вот так:
Ячейки с данными
Давайте разбираться, что же все-таки в коде происходит.
Мы видим два тега row — это наши строки. У каждой есть атрибут r — это номер строки. Атрибут spans означает сколько столбцов задействовано, dyDescent — вертикальное расстояние в пикселях между ячейками. Атрибут ht устанавливает высоту всей строки в пунктах, а тег customHeight говорит, что мы используем нестандартную высоту строки.
В теге row есть теги c — это ячейки в строке. у каждого тега есть атрибут r — означающий позицию ячейки. Но атрибут t — присутствует не у всех, потому что запись t=»s» — означает, что у ячейки установлен тип строки, а у кого этого атрибута нет — тип устанавливается стандартный — числовой. Еще у тегов c может присутствовать атрибут s, в котором записывается номер применяемого к ячейке стиля из файла xl/styles.xml (мы доберемся до него позже).
Но мы можем заметить, что одна ячейка имеет помимо тега v еще тег f. Это тег с формулой, в данном случае формула означает: сумма ячеек от A1 до E1. А в теге v записан уже посчитанный ответ. Делать это не обязательно, но если не записать — то при открытии документа excel предложит сохранить изменения, т.к. он сам автоматически посчитал и записал этот результат.
С тегом sheetData разобрались, идем дальше.
Как мы знаем, в Excel есть возможность объединения ячеек. Все объединенные ячейки на листе перечислены здесь. В заполненном виде тег выглядит примерно так:
Нетрудно понять, что атрибут ref задает зону, занимаемую активными ячейками фильтров.
Тег printOptions — параметры печати. Атрибут headings — означает, что будут печататься заголовки, а атрибут gridLines — что будут печататься линии сетки.
Тег pageMargins задает поля сверху, снизу, справа, слева, у заголовков и у подвала для печатаемой страницы.
Тег pageSetup предпочтительные настройки бумаги, опять же, для печати.
Атрибут paperSize — устанавливает размер бумаги.
Атрибут pageOrder — направление печати. Если значение «overThenDown» — то будет печататься слева направо, потом нижняя часть снова слева направо и т.д. Если такого атрибута нет — то печататься будет сначала вся левая сторона сверху-вниз, потом та часть, что справа и т.д.
Атрибут orientation — задает ориентацию листов. «portrait» — портретная (вертикальная) ориентация, «landscape» — альбомная (горизонтальная) ориентация.
Атрибут blackAndWhite — если установлена 1 ил true — лист будет напечатан в черно-белом варианте.
Атрибут draft — если установлена 1 ил true — лист будет напечатан без графики.
Атрибут cellComments — печать комментариев к ячейкам. Используемые значения:
Атрибут errors — Печать обработки ошибок.
Атрибут r:id — идентификатор настроек.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. X ML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
Это тоже самое, что передать в нем пустое значение

Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. Т ОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
Правильная вложенность элементов
Элементы могут идти друг за другом
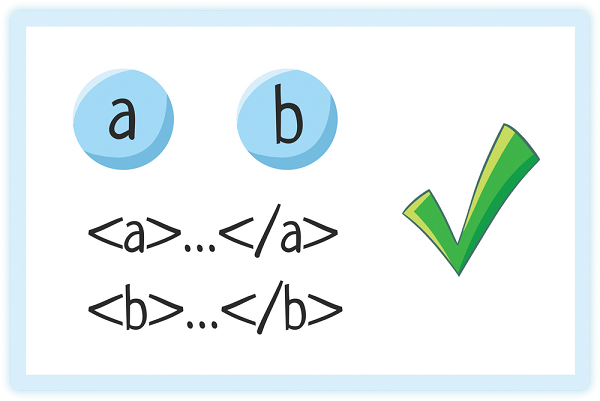
Один элемент может быть вложен в другой

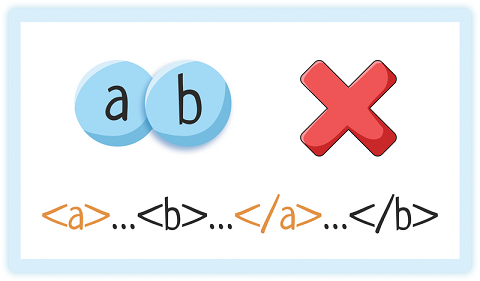
Но накладываться друг на друга элементы НЕ могут!
Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
Для тестирования пробуем передать его без кавычек:
Разбор xl/caclChain. xml
По традиции, начнем с содержимого файла:
Здесь нам важна строка 3. видим тег c — наша ячейка, у нее есть атрибут r — адрес ячейки. Индексный атрибут i указывает индекс листа, с которым связана ячейка.
Пространства имен
Сложные xml документы могут иметь вставки xml фрагментов различного назначения. И существует вероятность определения в этих фрагментов одинаковых имен элементов. Для избежания подобных конфликтов в xml используются пространства имен.
Пространство имен определяется в том элементе, в котором оно будет использоваться.
Либо можно вынести определения всех используемых пространств имен в корневой элемент.
Имя пространства имен задается как атрибут с префиксом xlmns: Значение должно быть
уникальным во всем документе, обычно это некий url адрес. Далее, чтобы указать нахождение элемента в определенном пространстве имен, используйте имя того пространства имен в качестве префикса имени элемента. В этом случае, имя элемента без префикса называется локальным именем.
Разбор docProps/app. xml
Содержимое данного файла примерно такая (не все элементы могут присутствовать и иметь тот же вид, что и у меня):
Первая строка нам уже знакома.
Во второй строке открывающий тег properties и эта строка похожа на рассмотренную нами ранее.
Третья строка содержит название приложения. В данном случае — Microsoft Excel (что не удивительно). Данную строку лучше не изменять, ибо приложение упадет.
Означает безопасность документа и в зависимости от числа имеет следующий посыл:
0 — Документ не защищен
1 — Документ защищен паролем.
2 — Рекомендуется открывать документ только для чтения.
4 — Документ принудительно открыт только для чтения.
8 — Документ заблокирован для заметок.
указывает режим отображения эскиза документа. Установите для этого элемента значение TRUE, чтобы включить масштабирование эскиза документа на экране. Установите для этого элемента значение FALSE, чтобы включить обрезку эскиза документа, чтобы отображались только те разделы, которые соответствуют отображаемому значению (из документации microsoft).
Далее открывается тег HeadingPairs, внутри которого описаны группы частей документа и количество частей в каждой группе. Эти части являются не частями документа, а концептуальными представлениями разделов документа.
Внутри HeadingPairs мы имеем 1 векторный контент, в котором имеются 2 его части (подробнее о векторах и baseType можно почитать в документации microsoft).
Первая часть означает, что мы описываем листы в книге, а во второй части указываем количество этих листов.
Следующий тег — TitlesOfParts. Он описывает наименования частей документа. в данном случае — названия листов в книге. Здесь также указывается количество частей векторного контента.
В теге Company можно записать название компании.
Следующий элемент — LinksUpToDate — указывает, актуальны ли гиперссылки в документе. Установите для этого элемента значение TRUE, чтобы показать, что гиперссылки обновлены. Установите для этого элемента значение FALSE, чтобы указать, что гиперссылки устарели (из документации microsoft).
HyperlinksChanged указывает, что одна или несколько гиперссылок в этой части были обновлены исключительно в этой части производителем. Следующий производитель, который откроет этот документ, обновит отношения гиперссылок новыми гиперссылками, указанными в этой части.
Тег AppVersion указывает версию используемого приложения Excel при создании файла
Поиск информации в XML файлах (XPath)¶
XPath ( англ. X ML Path Language) — язык запросов к элементам
XML-документа. X Path расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой
элемент (инструкция к дереву отношения не имеет).
У элемента дерева всегда существуют потомки и предки, кроме корневого
элемента, у которого предков нет, а также тупиковых элементов (листьев
дерева), у которых нет потомков. Каждый элемент дерева находится на
определенном уровне вложенности (далее — «уровень»). У элементов на
одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки
XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример
списка книг:
XPath запрос вернет следующий результат:
Сокращенная форма этого запроса выглядит так: .
Everyday Italian
Giada De Laurentiis
2005
30.00
В приведенной ниже таблице представлены некоторые выражения XPath и
результат их работы:
Разбор [Content_Types]. xml
Содержимое файла может быть следующим:
В этом файле прописываются определения типов всех файлов и их расположения.
Как видно, здесь записываются все файлы листов, стилей, строковых значений, формул и т.д.
Если в документе вы не используете, к примеру, формул, то строки 13 не будет записано.
Завершение
Я разобрал основные моменты содержания файла excel. Если вам будет интересно узнать про диаграммы и другие возможности excel — пишите в комментариях, я постараюсь сделать дополнение к этой статье из ваших просьб.
Каждому человеку свойственно ошибаться. Если я чего-любо не раскрыл или раскрыл не полностью, либо с ошибками — поправьте меня.
Если вам также будет интересно — напишу статью, как манипулировать с файлами excel посредством PHP/Java/Ruby.
Спасибо за внимание и уделенное время этой статье.
XPath — средство поиска информации в xml документе, используемое различными
xml технологиями. Например, XPath выражения могут использоваться в XSLT.
Для построени XPath шаблонов используются следующие элементы:
Пусть имеет следующий xml документ, содержащий книги по жанрам.
Тогда XPath шаблоны могут выглядеть следующим образом:
Удаление лишних блоков(абзацев) из XML по заданному условию¶
Теги в структуре XML образуют многострочные блоки. Иногда возникает необходимость удалить ряд целых блоков по заданному условию. В качестве примера будет рассмотрена ситуация с отчетом по НДС.
Для передачи налоговой отчетности по ТКС в контролирующие органы используется XML. Весь учет ведется в одних программах (например, в 1С), затем выгружается из них в xml формате и отправляется по ТКС непосредственно в контролирующие органы.
Из-за несовершенства некоторых программ, периодически возникают проблемы при передаче файлов в контролирующие органы.
Суть проблемы¶
Отрывок книги продаж выглядит следующим образом:
01
02
А нижеприведенный блок в Книге продаж необязателен:
Если есть сделки с иностранными контрагентами, у которых нет ИНН/КПП, следовательно, сведения о покупателе не заполняются. Но из-за логической ошибки в программе бухгалтерского учета, выгрузка сформированного отчета была невозможна, так как программа ошибочно требовала указать ИНН/КПП для всех контрагентов.
Чтобы обойти эту ошибку пришлось вместо ИНН указать регистрационный номер контрагента в стране регистрации, а вместо КПП указать девять нулей.
Но при попытке отравить выгруженный отчет в контролирующий орган, возникала обратная ошибка. Так как ИНН и КПП были фиктивными, то при проверке отчета не выполнялись контрольные соотношения.

Проверка файла отчета программой Tester
ИНН и КПП это не произвольный набор чисел, они содержат определенные контрольные соотношения.
Теперь следовало вручную исправить XML файл отчета и удалить лишние блоки с фиктивными данными.
Решение проблемы¶
Так как файл содержал свыше 15000 строк и большое количество сделок, надо было автоматизировать данный процесс.

Надо было удалить порядка 700 строк, полностью содержащих блоки (причем
с разными псевдо-ИНН):
Большинство программ умеет искать и заменять максимум одну строку на
другую. В данном случае надо было искать и заменять блок текста из трех
строк.
С этим успешно справилась программа UVFilesCorrector. Интерфейс программы прост до невозможности. В нижней части на вкладке Файлы выбираем нужный нам файл.

В верхнем поле Список замен необходимо нажать на пустое поле и создаем правило для замены. В данном случае оно выглядело так:

На скриншоте видно не все выражение, в поле Что найти: в режиме
Шаблон (регулярное выражение) введено:
Всего у организации было 14 контрагентов, с которыми в общей сумме было
заключено 266 сделок. Следовательно, после нажатия на кнопку Заменить
получилось 266 замены.

Буквально за один простой шаг по заданному условию было удалено свыше
700 строк. Проверка Tester’ом ошибок не выявила и файл был успешно отправлен в контролирующий орган.
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам.
XML документ отвечающий этим правилам называется валидным (англ.
Valid — правильный) или синтаксически верным. Соответственно, если
документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
Открывающий и закрывающий теги должны определяться в одном регистре:
Это неправильно
Это правильно
Некорректная вложенность
Корректная вложенность
В большинстве XML файлов отчетов для ФНС корневым элементом является . После закрывающего тега больше ничего быть не должно.
Корректная запись
Некорреткная запись
Обзор DOM3 XML
Объектная модель документа (DOM) представляется как иерархия узлов,
объектов с интерфейсом Node. Остальные интерфейсы являются расширением Node:
Кроме этого есть дополнительные вспомогательные интерфейсы как NodeList.
Разбор xl/worksheets/_rels/sheet1. xml. rels
Содержимое этого файла может быть следующим:
Здесь описана одна зависимость с файлом xl/printerSettings/printerSettings1.bin — настройками для печати.
Разбор xl/sharedStrings. xml
В этом примере строковое значение содержит 3 пробега. Чтобы было удобнее их рассматривать, я, пожалуй, вынесу их отдельными сорсами.
А здесь у нас есть и блок настроек шрифта, и сохранение концевых пробелов.
Ну и еще коротенькая ремарка. Если есть необходимость сделать многострочную запись в ячейке, то здесь в строке просто будет обычный символ переноса, chr. Сам атрибут многострочности ячейки расположен в файле разметки листа. В однострочной ячейке символ переноса будет проигнорирован. Excel просто сделает вид, что его нет.
Добавлю: каждый тег si имеет порядковый номер, начиная с 0. Он нигде не записывается. Этот номер и записывается в файле xl/worksheets/sheet1.xml в теге sheetData, который мы рассматривали ранее.
Структура xml файла
Необязательный заголовок определяет версию xml и, если нужно, кодировку.
Для русско-язычных значение кодировки может быть Windows-1251 или KOI-8.
Комментарий
Указание типа документа не обязательно, но его наличие будет означать
валидность документа.
Ниже приведен небольшой пример определения типа документа внутри документа.
Здесь root_el задает имя корневого элемента.
По необходимости в квадратных скобках можно уточнить какие элементы может
содержать корневой элемент. В нашем примере root_el может
содержать один элемент el1, и несколько элементов el2. Далее можно уточнить каждый
элемент в отдельности. В нашем примере мы указали, что элемент el1 и el2 содержат данные.
Описание документа можно вынести в отдельный файл, а в xml файле делать только ссылку на него
(относительный или полный url).
Приватные описания указываются после слова SYSTEM. Публичные (стандартизованные) указываются
после PUBLIC. Файл с описанием обычно имеет расширение dtd.
Можно объединить оба варианта, при условии, что имена элементов во внешнем файле не совпадают
с именами элементов определенных внутри документа.
Элементы
Дополнительную информацию об элементе можно указать с помощью атрибутов.
Они указываются в открывающем теге после имени элемента как имя_атрибута=»значение».
Атрибутов может быть несколько.
Дерево элементов
Дерево элементов порождается вложением одних элементов в другие.
Каждый открывающий тег должен иметь закрывающий. Элементы должны быть вложены правильно.
Вне корневого элемента не должно быть текста, или других элементов.
Чтобы избежать ошибок вложения и не закрытых тегов, рекомендуется придерживаться форматирования, т.е. размещать элементы на отдельной строке, вложенность показывать пробелами.
Работа с файлами отчетов Росстата¶
Файлы отчетов Росстата формируются в одну строку, что создает определенные сложности при просмотре в обычных тектовых редакторах.

В отличии, например, от файлов отчетов ФНС.

С файлами Росстата лучше работать с помощью программы XMLPad.
XMLPad имеет несколько режимов отображения:

В левой панели отображается структура XML-файла. Значения элементов можно отреактировать напрямую, либо через левую нижнюю панель.







