
 для начинающих часть 1")
Время на прочтение

В этой части я расскажу о работе с параметрами и переменными внутри SSIS-пакета. Узнаем, как можно задавать и отслеживать значения переменных во время выполнения пакета.
Также рассмотрим вызов одного пакета из другого при помощи «Execute Package Task» и некоторые дополнительные компоненты и решения.
Здесь тоже будет много картинок.
Microsoft SQL Server Integration Services (SSIS) is a component of the Microsoft SQL Server database software that can be used to perform a broad range of data migration tasks.
SSIS is a platform for data integration and workflow applications. It features a data warehousing tool used for data extraction, transformation, and loading (ETL). The tool may also be used to automate maintenance of SQL Server databases and updates to multidimensional cube data.
SSIS – это инструмент, который позволяет в удобном виде реализовать интеграцию, т.е. реализовать процесс переноса данных из одного источника в другой. Этот процесс иногда называют ETL (от англ. Extract, Transform, Load – дословно «извлечение, преобразование, загрузка»).
Думаю, данный практический курс будет полезен тем, кто хочет изучить SSIS и не знает с чего начать. Здесь в режиме Step By Step мы начнем с самого начала, т.е. установки всего необходимого.
Дальше будет очень много картинок!
В этой части изменим логику загрузки справочника Products:
В завершении этой части рассмотрим компонент Multicast для того чтобы распараллелить выходящий набор.
Итого в этой части мы познакомимся с четырьмя новыми компонентами: Union All, Lookup, OLE DB Command и Multicast.
Дальше так же будет очень много картинок.
- «Integration Services Transformations». Microsoft Developer Network. Microsoft. Retrieved 2013.
- «Cache Transform». Microsoft Developer Network. Microsoft. Retrieved 2013.
- «Percentage Sampling Transformation». Microsoft Developer Network. Microsoft. Retrieved 2013.
- «Developing a Custom Data Flow Component». Microsoft Developer Network. Microsoft. Retrieved 2013.
- «Developing a Custom Task». Microsoft Developer Network. Microsoft. Retrieved 2013.
A connection includes the information necessary to connect to a particular data source. Tasks can reference the connection by its name, allowing the details of the connection to be changed or configured at run time.
A workflow can be designed for a number of events in the different scopes where they might occur. In this way, tasks may be executed in response to happenings within the package — such as cleaning up after errors.
Parameters (SQL Server 2012 Integration Services)
Parameters allow you to assign values to properties within packages at the time of package execution. You can have project parameters and package parameters. In general, if you are deploying a package using the package deployment model, you should use configurations instead of parameters.
Tasks are linked by precedence constraints. The precedence constraint preceding a particular task must be met before that task executes. The run time supports executing tasks in parallel, if their precedence constraints so allow. Constraints may otherwise allow different paths of execution depending on the success or failure of other tasks. Together with the tasks, precedence constraints comprise the workflow of the package.
A task is an atomic work unit that performs some action. There are a couple of dozen tasks that ship in the box, ranging from the file system task (that can copy or move files) to the data transformation task. The data transformation task actually copies data; it implements the ETL features of the product
Tasks may reference variables to store results, make decisions, or affect their configuration.
A package may be saved to a file or to a store with a hierarchical namespace within a SQL Server instance. In either case, the package content is persisted in XML.
- Features of the data flow task
- Продолжим знакомство с SSIS
- Установка SQL Server и SSDT
- Создание задачи в SQL Server Agent
- Extensibility and programmability
- Необходимые инструменты для изучения SSIS
- Other included tools
- Создание SSIS проекта
- Развертывание SSIS
- Заключение по второй части
- Заключение по третьей части
- Заключение по первой части
Features of the data flow task
Запустим SQL Server Management Studio (SSMS) и при помощи скрипта создадим 3 базы данных – первые две (DemoSSIS_SourceA и DemoSSIS_SourceB) будут выступать в роли источников данных, а третья (DemoSSIS_Target) в роли получателя данных:
— первая БД выступающая в роли источника данных
CREATE DATABASE DemoSSIS_SourceA
GO
ALTER DATABASE DemoSSIS_SourceA SET RECOVERY SIMPLE
GO
— вторая БД выступающая в роли источника данных
CREATE DATABASE DemoSSIS_SourceB
GO
ALTER DATABASE DemoSSIS_SourceB SET RECOVERY SIMPLE
GO
— БД выступающая в роли получателя данных
CREATE DATABASE DemoSSIS_Target
GO
ALTER DATABASE DemoSSIS_Target SET RECOVERY SIMPLE
GO
В базах источниках создадим тестовые таблицы и наполним их тестовыми данными:
USE DemoSSIS_SourceA
GO
— продукты из источника A
CREATE TABLE Products(
ID int NOT NULL IDENTITY,
Title nvarchar NOT NULL,
NOT NULL,
Price money,
CONSTRAINT PK_Products PRIMARY KEY(ID)
)
GO
— наполняем таблицу тестовыми данными
SET IDENTITY_INSERT Products ON
INSERT Products(ID,Title,Price)VALUES
(1,N’Клей’,20),
(2,N’Корректор’,NULL),
(3,N’Скотч’,100),
(4,N’Стикеры’,80),
(5,N’Скрепки’,25)
SET IDENTITY_INSERT Products OFF
GO
USE DemoSSIS_SourceB
GO
— продукты из источника B
CREATE TABLE Products(
ID int NOT NULL IDENTITY,
Title nvarchar NOT NULL,
Price money,
CONSTRAINT PK_Products PRIMARY KEY(ID)
)
GO
— наполняем таблицу тестовыми данными
SET IDENTITY_INSERT Products ON
INSERT Products(ID,Title,Price)VALUES
(1,N’Ножницы’,200),
(2,N’Нож канцелярский’,70),
(3,N’Дырокол’,220),
(4,N’Степлер’,150),
(5,N’Шариковая ручка’,15)
SET IDENTITY_INSERT Products OFF
GO
Создадим таблицу в принимающей базе:
USE DemoSSIS_Target
GO
— принимающая таблица
CREATE TABLE Products(
ID int NOT NULL IDENTITY,
Title nvarchar NOT NULL,
Price money,
SourceID char
NOT NULL, — используется для идентификации источника
SourceProductID int NOT NULL, — ID в источнике
CONSTRAINT PK_Products PRIMARY KEY(ID),
CONSTRAINT UK_Products UNIQUE(SourceID,SourceProductID),
CONSTRAINT CK_Products_SourceID CHECK(SourceID IN(‘A’,’B’))
)
GO
Продолжим знакомство с SSIS
Создадим новый пакет:
И переименуем его в «LoadProducts_ver2.dtsx»:
В области «Control Flow» создадим «Data Flow Task»:
Двойным щелчком по элементу «Data Flow Task» зайдем в его область «Data Flow». Создадим два элемента «Source Assistant» для соединений SourceA и SourceB. Переименуем эти элементы в «Source A» и «Source B» соответственно:
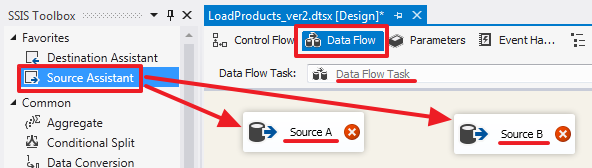
«Source A» настроим следующим образом:

SELECT
ID SourceProductID,
Title,
Price
FROM Products
В целях демонстрации больших возможностей за раз, здесь я намеренно отпустил SourceID.
«Source B» настроим следующим образом:
SELECT
ID SourceProductID,
‘B’ SourceID,
Title,
Price
FROM Products
Воспользуемся элементом «Union All», чтобы объединить данные из 2-х наборов в один. Направим в него синие стрелки из «Source A» и «Source B»:
Каким образом делается сопоставление колонок двух входящих наборов, можно увидеть дважды щелкнув на элементе «Union All»:
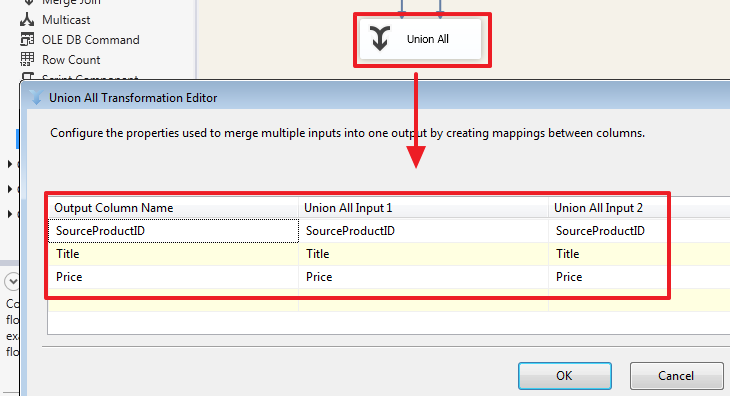
Как мы видим, здесь сделалось автоматическое сопоставление колонок имена которых совпадают. При необходимости мы можем сделать свое сопоставление, для примера добавим колонку SourceID из второго набора:
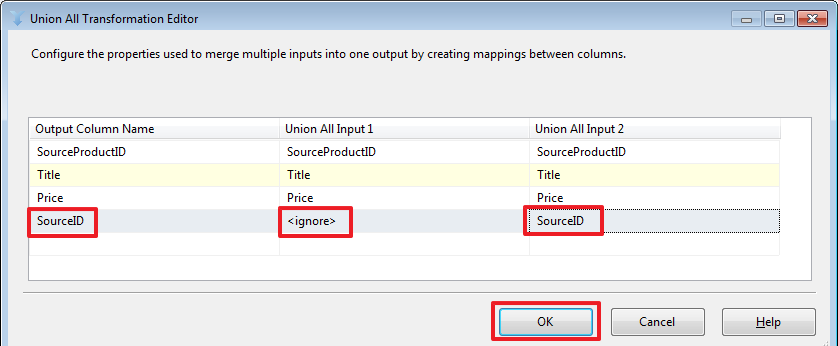
В данном случае значения SourceID набора «Source A» будут равны NULL.
Объединение двух наборов в данном случае делается на стороне SSIS. Здесь стоит обратить внимание на то, что базы источники и принимающая база могут располагаться на разных серверах/экземплярах SQL Server, по этой причине мы не всегда сможем так просто написать SQL запрос используя в нем таблицы из разных баз с применением SQL-операции UNION или JOIN (который можно было использовать вместо Lookup описанного ниже).
Для того чтобы заменить NULL значения на «A» воспользуемся компонентом «Derived Column» в который направим поток из «Union All»:

Двойным щелчком зайдем в редактор «Derived Column» и настроим его следующим образом:

Проделаем следующее (мышь в помощь):
Для того чтобы понять, что произошло с данными после прохождения «Union All» сделайте «Enable Data Viewer» для стрелки, идущей от «Union All» к «Derived Column»:

Теперь при запуске пакета на выполнение вы сможете увидеть набор, который получился в результате:

Здесь видно, что на этом этапе (до Derived Column) в колонке SourceID для строк первого набора стоят значения NULL.
Для того чтобы определить была ли добавлена ранее запись в базу DemoSSIS_Target воспользуемся компонентом Lookup:

Дважды щелкнув по нему настроим данный элемент:

Здесь мы скажем, что те строки, для которых не найдено соответствие, мы будем перенаправлять в поток «no match output». В этом случае на выходе мы получим 2 набора «Lookup Match Output» и «Lookup No Match Output».
Например, если выставить значение «Ignore failure», то в строках, для которых не нашлось сопоставления в поле TargetID (см. ниже) будет записано значение NULL и все строки будут возвращены через один набор «Lookup Match Output».
«Full cache» говорит о том, что набор, который будет использоваться в качестве справочника одним SQL запросом (см.на следующей вкладке) будет полностью загружен в память и строки будут сопоставляться уже с кэша без повторных обращений к SQL Server.
Если же выбрать «Partial cache» или «No cache», то на вкладке Advanced можно будет прописать запрос с параметрами, который будет выполняться для сопоставления каждой строки входящего набора. Для интереса можно поиграться с этим свойством и через SQL Server Profiler посмотреть какие будут формироваться запросы при выполнении пакета.
На следующей вкладке нам нужно определить набор, который будет выступать в роли справочника:

Я прописал здесь запрос:
SELECT
SourceID,
SourceProductID,
ID TargetID
FROM Products
На следующей вкладке нужно указать по каким полям делается поиск строки в справочнике и какие колонки из справочника нужно добавить в выходной набор (если это нужно):

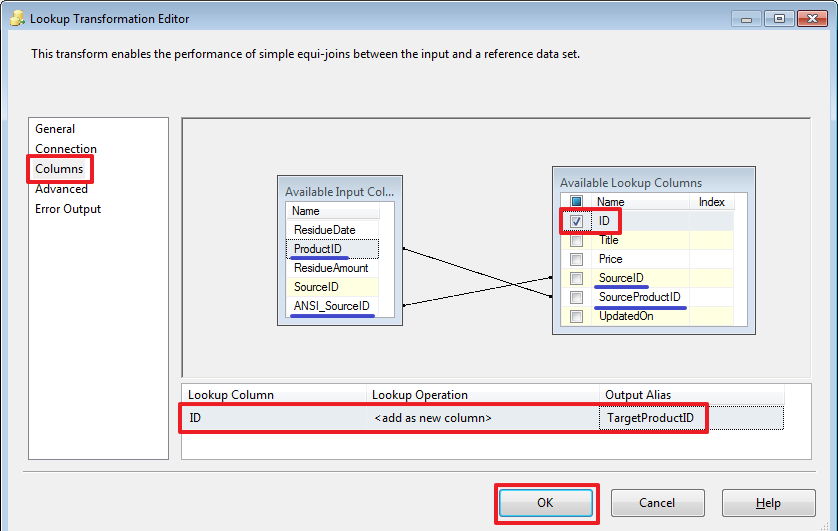
Для определение связи нужно при помощи мыши перетащить поле SourceProductID на SourceProductID и поле SourceID на SourceID.
Добавим компонент «Destination Assistant» для вставки записей с потока «Lookup No Match Output»:

Перетащим синюю стрелку с «Lookup» на «OLE DB Destination» и в диалоговом окне выберем поток «Lookup No Match Output»:

В итоге мы получим следующее:
Дважды щелкнув по «OLE DB Destination» настроим его:


Обработку вставки новых записей мы сделали.
Теперь для обновления ранее вставленных записей воспользуемся компонентом «OLE DB Command» и перенесем на него синюю стрелку от Lookup:

В этот компонент автоматически будет направлен поток «Lookup Match Output», т.к. поток «Lookup No Match Output» мы уже выбрали ранее:
Дважды щелкнем на «OLE DB Command» и настроим его:

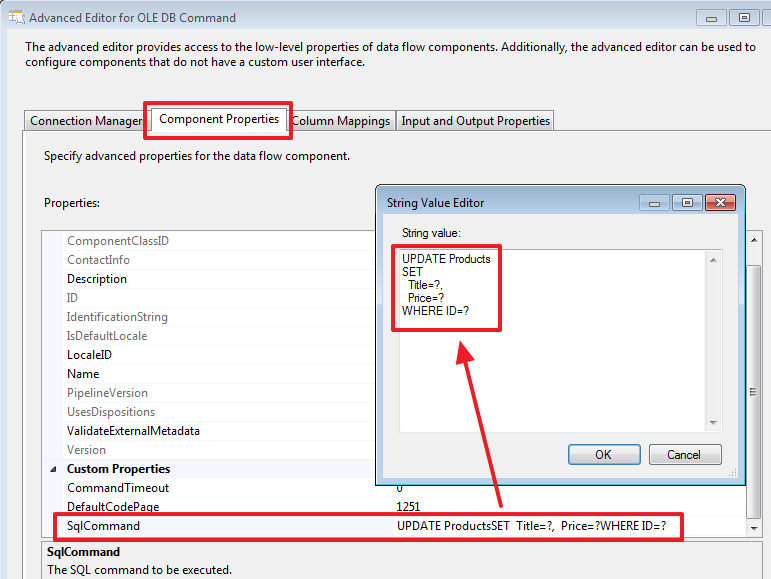
Пропишем следующий запрос на обновление:
UPDATE Products
SET
Title=?,
Price=?
WHERE ID=?
На следующей вкладке укажем каким образом будут задаваться параметры на основании данных строк входящего набора «Lookup Match Output»:

Через SSMS добавим новых продуктов в базу DemoSSIS_SourceB:
USE DemoSSIS_SourceB
GO
— добавим новых товаров
SET IDENTITY_INSERT Products ON
INSERT Products(ID,Title,Price)VALUES
(6,N’Точилка’,NULL),
(7,N’Ластик’,NULL),
(8,N’Карандаш простой’,NULL)
SET IDENTITY_INSERT Products OFF
GO
Для того чтобы отследить как менялись данные, вы можете, перед запуском пакета на выполнение, в необходимых местах сделать «Enable Data Viewer»:

Запустим пакет на выполнение:

В итоге мы должны увидеть, что 3 строки было вставлено при помощи компонента «OLE DB Destination» и 10 строк обновлено при помощи компонента «OLE DB Command».
Запрос прописанный в «OLE DB Command» выполнился для каждой строки входящего набора, т.е. в данном примере 10 раз.
В «OLE DB Command» можно прописать более сложную логику на TSQL, например, сделать проверку, были ли изменены Title или Price, и делать обновление соответствующей строки только если какое-то из значений отличается.
Для наглядности добавим новую колонку в таблицу Products в базе DemoSSIS_Target:
USE DemoSSIS_Target
GO
ALTER TABLE Products ADD UpdatedOn datetime
GO
Давайте теперь пропишем следующую команду:

Так же можно было бы все это оформить в виде хранимой процедуры, а здесь прописать ее через вызов «EXEC ProcName ?,?,?». Здесь, думаю, кому как удобнее, мне порой удобнее, чтобы все было прописано в одном месте, т.е. в SSIS-проекте. Но если использовать процедуру, то тоже получаем свои удобства, в этом случае можно, было бы просто изменить процедуру и избежать переделки и повторного развертывания SSIS-проекта.
После чего переопределим привязку параметров согласно их очередности в тексте команды:
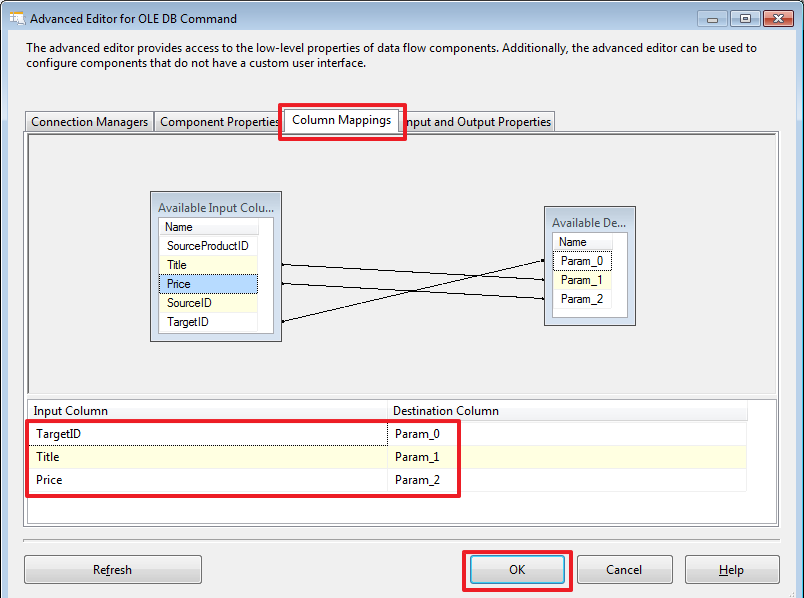
Сделаем в базе DemoSSIS_SourceA обновление:
USE DemoSSIS_SourceA
GO
UPDATE Products
SET
Price=30
WHERE ID=2 — Корректор
И снова запустим проект на выполнение. В результате после очередного запуска пакета на выполнение, UPDATE должен будет выполниться только 1 раз, только для этой записи.

После выполнения пакета проверим это при помощи запроса:
USE DemoSSIS_Target
GO
SELECT *
FROM Products
ORDER BY UpdatedOn DESC

В рамках данной части рассмотрим еще компонент «Multicast». Данный компонент позволяет получить из одного потока несколько. Это может быть полезно, когда одни и те же данные необходимо записать в два или более разных мест – т.е. входит один набор, а выходит столько его копий сколько нам нужно, и с каждой копией этого набора мы можем делать что захотим.
Для примера создадим в базе DemoSSIS_Target еще одну таблицу LastAddedProducts:
USE DemoSSIS_Target
GO
CREATE TABLE LastAddedProducts(
SourceID char
NOT NULL, — используется для идентификации источника
SourceProductID int NOT NULL, — ID в источнике
Title nvarchar
NOT NULL,
Price money,
CONSTRAINT PK_LastAddedProducts PRIMARY KEY(SourceID,SourceProductID),
CONSTRAINT CK_LastAddedProducts_SourceID CHECK(SourceID IN(‘A’,’B’))
)
GO
Для очистки этой таблицы добавим в область «Control Flow» компонент «Execute SQL Task» и пропишем в нем команду «TRUNCATE TABLE LastAddedProducts»:


Перейдем в область «Data Flow» компонента «Data Flow Task» и добавим компонент следующим образом:
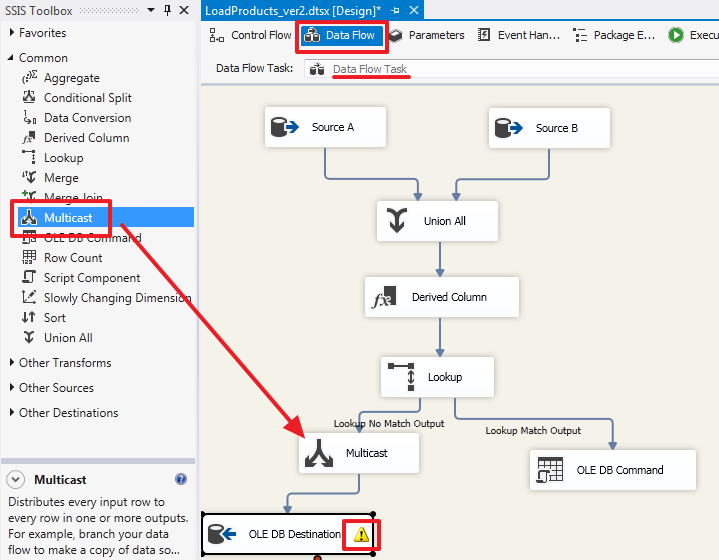
Обратите внимание на желтый восклицательный знак – это произошло из-за того, что мы добавили колонку UpdatedOn и не привязали ее. Зайдем в элемент «OLE DB Destination», перейдем на вкладку Mappings оставим для колонки UpdatedOn в качестве входящего поля Ignore и нажмем OK:

Создадим еще один элемент «OLE DB Destination» и перетащим на него вторую синюю стрелку от элемента Multicast:

Переименуем для наглядности:
Настроим «To LastAddedProducts»:
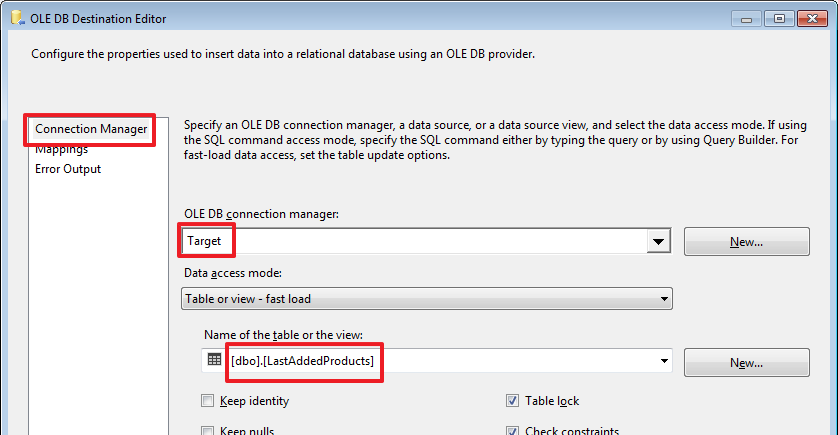
Удалим через SSMS три последние вставленные записи:
И запустим пакет на выполнение:

В итоге добавление произошло в 2 таблицы – Products и LastAddedProducts.
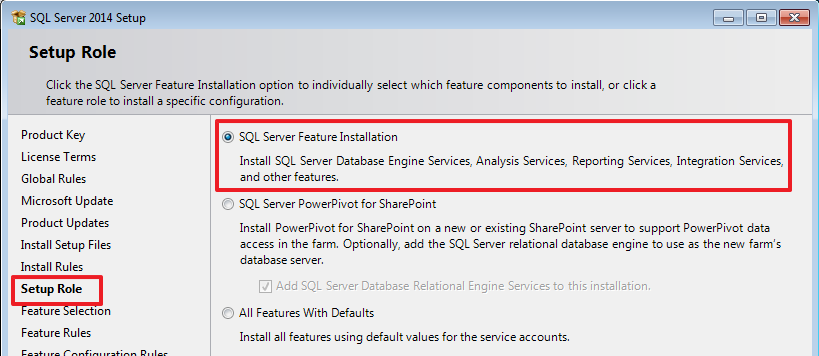
Установка SQL Server и SSDT
Первым делом установим SQL Server со всеми необходимыми компонентами.
Я все устанавливал на чистую Windows 7 SP 1 (x64), ничего дополнительного кроме указанного ниже устанавливать не придется.
Т.к. курс предназначен для начинающих, то распишу весь процесс установки подробно.
Запускаем установочный файл SQL Server 2014:

Для работы SSIS достаточно будет выбрать следующие компоненты:
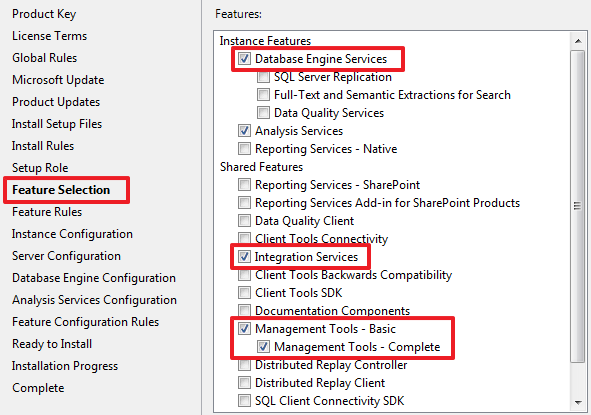
Т.к. мне в дальнейшем понадобится Analysis Services (SSAS), то я отметил и его, если он вам не нужен вы можете не выбирать данный компонент.
У меня нет других установленных SQL Server, и я сделаю этот экземпляр используемым по умолчанию:

Сделаю, чтобы SQL Agent запускался автоматически:

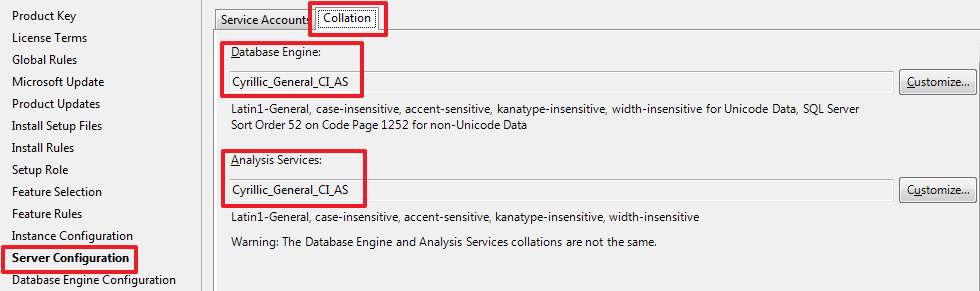
При необходимости можно изменить Collation, который будет использоваться по умолчанию:
Установлю смешанный режим аутентификации, указав свой пароль для пользователя sa:

Т.к. я еще выбрал Analysis Services, то делаю настройки для него:

Нажимая Next и Install запускаем установку SQL Server и его компонент.
Так как у меня на компьютере всего один диск, то все директории я оставил по умолчанию, при необходимости вы можете изменить их на более удобные.
Следующим шагом установим SSDT – это расширение для Visual Studio, которое даст нам возможность создавать проекты SSIS. Установщик SSDT ставит минимальную версию оболочки VS, поэтому предварительно устанавливать VS отдельно нет надобности.
Запускаем «SSDTBI_VS2012_x86_ENU.exe», и добравшись до следующего шага выбираем следующий пункт:

Нажимая Next запускаем установку.
После завершения установки на всякий случай перезагружаем компьютер.
Это все, что нам понадобится для изучения SSIS.
Создание задачи в SQL Server Agent
Создадим задачу в SQL Agent, для выполнения пакета по расписанию:

Создаем новый шаг:
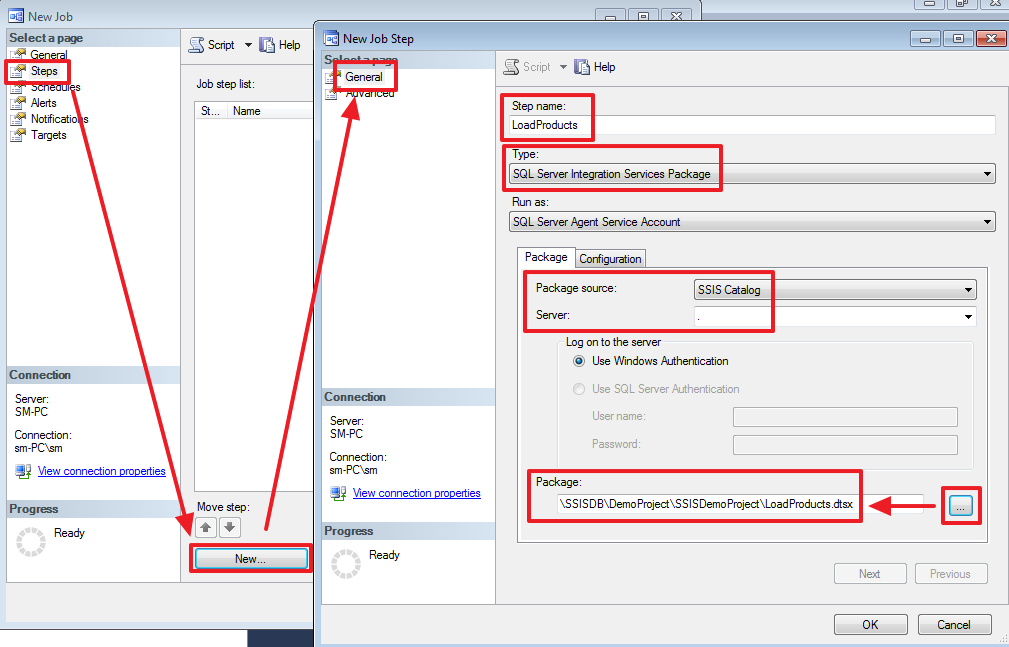

На закладке Advanced можно изменить логику, которая будет использоваться при успешном или неуспешном завершении шага:


Осталось создать расписание для данной задачи:

Расписание можно задать разнообразным образом. Думаю, здесь все должно быть интуитивно понятно:

Все, задача создана.
Делаем тестовый запуск:

Так как шаг у нас всего один, то задача запустится сразу, иначе нужно было бы указать с какого шага нужно начать выполнение.
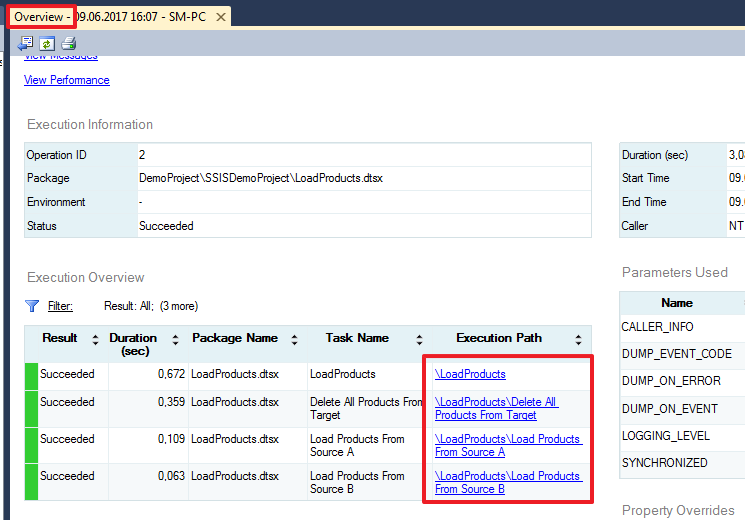
Результат выполнения задачи можно увидеть в следующем журнале:

В данном журнале можно увидеть успешность завершения каждого шага, а также время выполнения и прочие параметры.
Более подробный отчет о выполнении пакета можно посмотреть при помощи следующего отчета:


Extensibility and programmability
SSIS features a programmable object model that allows developers to write their own hosts for package execution. Such a host can respond to events, start and stop packages, and so on. The object model also allows developers to create, store, and load packages, as well as create, destroy, and modify any of the contained objects.
Within limits, SSIS packages can load and call CLI assembly DLLs, providing access to virtually any kind of operation permissible by the . NET CLR.
SSIS can be used on all SQL Server 2005, 2008, 2008 R2, 2012, 2014 and 2016 editions except Express and Workgroup.
Необходимые инструменты для изучения SSIS
В данной статье SSIS будет рассматриваться на примере SQL Server 2014 Developer Edition. Службы Integration Services доступны в SQL Server 2014 начиная с редакции Standard.
SSDT – это расширение для Visual Studio, которое позволит создавать проекты необходимого нам типа.
По описанию, данная версия SSDT поддерживает следующие версии SQL Server: SQL Server 2014, SQL Server 2012, SQL Server 2008 и 2008 R2.
Если на вашем компьютере не установлен VS данной версии, то установщик SSDT установит минимальную версию оболочки, которая позволит создавать проекты нужного нам типа.
Other included tools
Aside from the Import/Export Wizard and the designer, the product includes a few other notable tools.
Создание SSIS проекта
Запустим Visual Studio 2012 и выберем один из видов предлагаемой нам настройки среды, так здесь же я откажусь от локальной документации:

Для последующего облегчения развертывания зайдем в свойства проекта и изменим опцию ProtectionLevel на DontSaveSensitive:

То же самое сделаем в свойствах пакета, который создался по умолчанию:
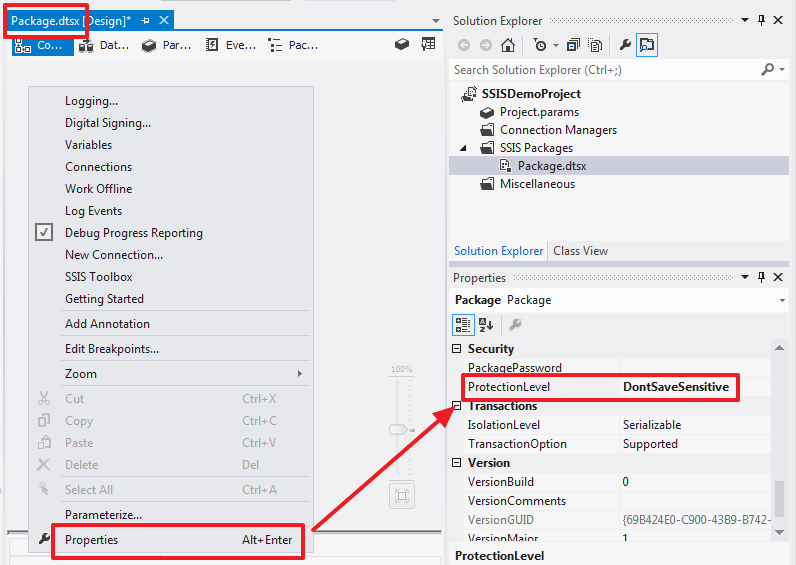
Для всех новых пакетов данное свойство будет заполняться значением из свойства проекта.


Заполняем параметры соединение с БД:

Боевые параметры соединения в дальнейшем можно будет настроить при создании задачи SQL Server Agent.

Для удобства я переименую название соединения на SourceA:

Таким же образом создадим и переименуем соединения для баз DemoSSIS_SourceB и DemoSSIS_Target:
Переименуем пакет, созданный по умолчанию, в «LoadProducts.dtsx»:
Сначала напишем простую логику, которая будет полностью очищать таблицу Products в базе DemoSSIS_Target и снова загружать в нее данные из двух баз данных DemoSSIS_SourceA и DemoSSIS_SourceB.
Для очистки воспользуемся компонентом «Execute SQL Task», который мы при помощи мыши создадим в области «Control Flow»:
Для наглядности можно переименовать название компонент. Зададим ему имя «Delete All Products From Target»:
Для этой цели используется свойство Name.
Дважды щелкнем на этом элементе и пропишем следующие свойства:

Т.к. T SQL команда «TRUNCATE TABLE Products» ничего не возвращает оставим свойства ResultSet равным None.
В дальнейшем мы рассмотрим, как пользоваться параметрами и каким образом можно воспользоваться результатом выполнения команды, записанной в SQLStatement, а пока попытаемся увидеть всю картину как это работает в целом.
Теперь скинем в область «Control Flow» компонент «Data Flow Task» и переименуем его в «Load Products From Source A», а также протянем к этому компоненту зеленную стрелку от «Delete All Products From Target»:
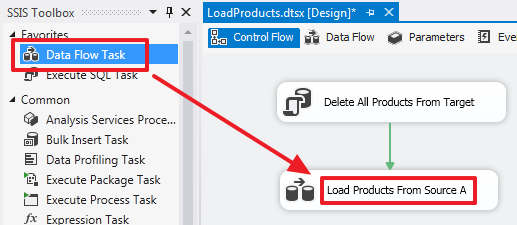
Таким образом мы создали цепочку, которая будет выполняться последовательно.
Щелкнув дважды на «Load Products From Source A» мы попадаем в область «Data Flow» этого элемента.
Data Flow Task – это сложный компонент, который имеет свою область, в которой создаются вложенные элементы для работы с потоком данных.
Скинем в эту область компонент «Source Assistant»:

Этот компонент отвечает за получение данных из источника. Дважды щелкнув по нему, мы сможем настроить его:

На закладке Columns мы можем выбрать только необходимые нам колонки и при необходимости переименовать их прописав новое имя в колонке «Output Columns»:

Для получателя нужна еще одна дополнительная колонка SourceID, добавим ее к выходному набору при помощи компонента «Derived Column», который переименуем в «Add SourceID», так же протянем синюю стрелку к данному элементу от «OLE DB Source»:

Дважды щелкнем по элементу «Add SourceID» и пропишем значение «A» в виде константы:

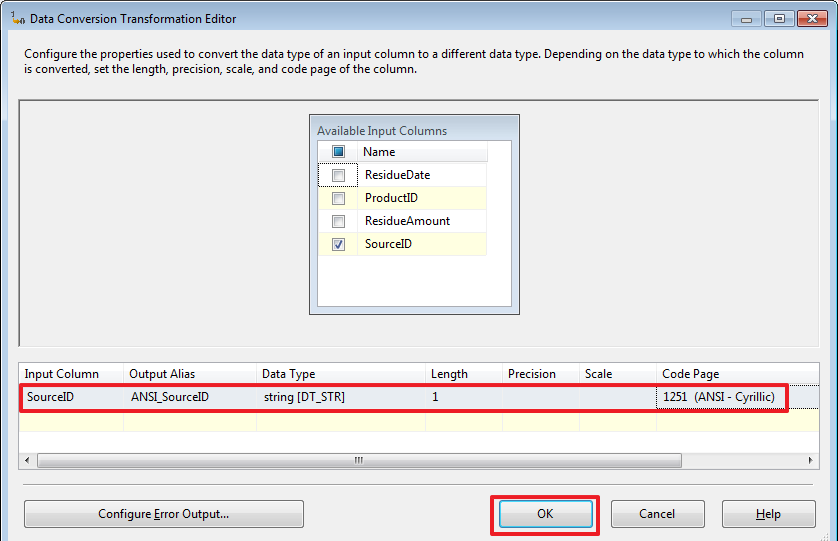
Здесь я воспользовался функцией преобразования типа (DT_STR,1,1251) для того чтобы превратить Unicode строку в ANSI.
Теперь создадим компонент «Destination Assistant»:

Направим в него поток от «Add SourceID»:
Дважды щелкнем по «OLE DB Destination» и произведем настройки:
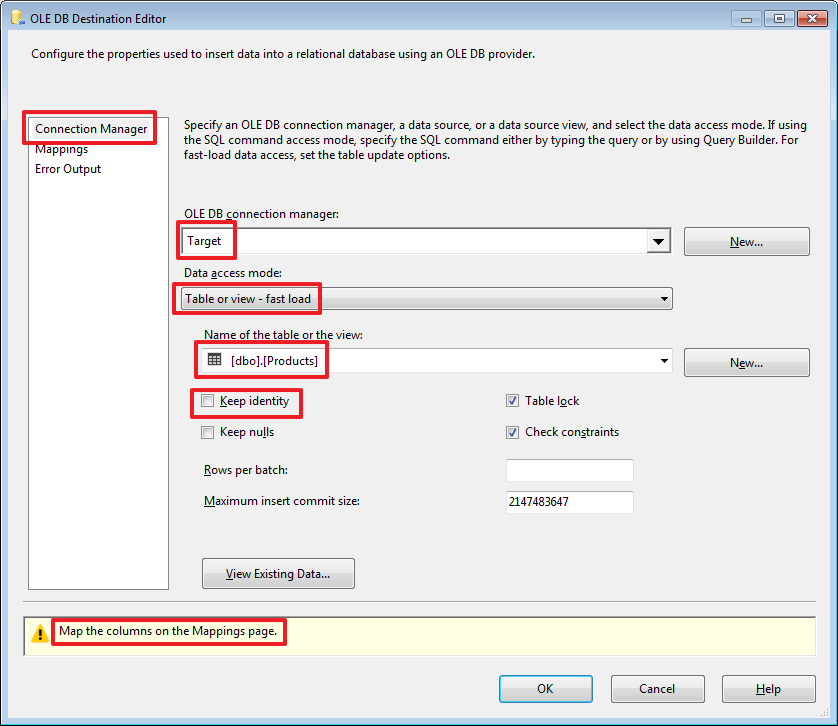
Здесь мы показываем в какую таблицу будет записываться полученный набор.
«Keep identity» используется в случае если в принимающей таблице есть поле с флагом IDENTITY и мы хотим, чтобы значения в него тоже записывались из источника (это аналогично включению опции SET IDENTITY_INSERT Products ON).
Перейдя на закладку Mappings осуществим привязку полей источника с полями получателя:
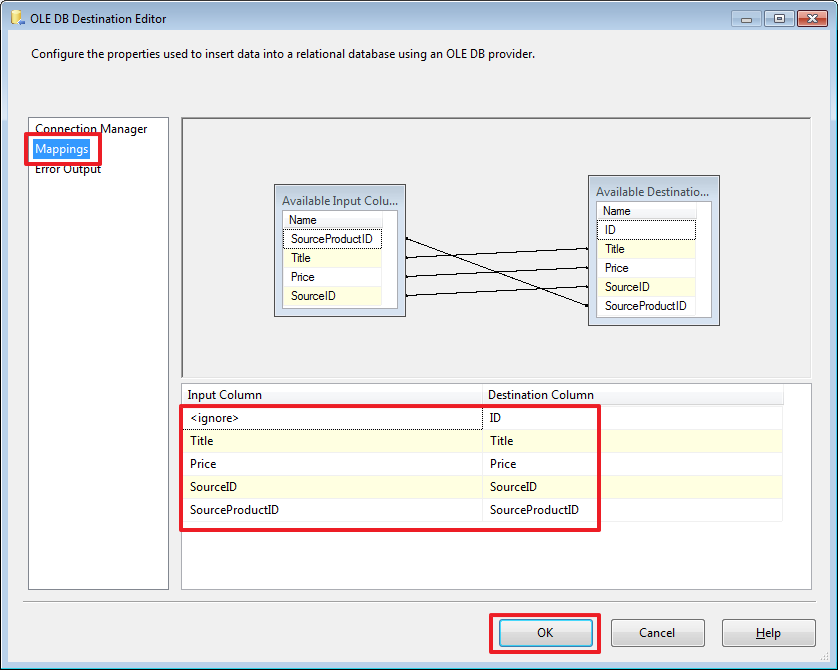
Так как у нас поля источника и приемника именуются одинаково, то привязка осуществилась автоматически.
Можем протестировать работу пакета и убедиться, что данные залились в таблицу Products базы DemoSSIS_Target.
Запускаем пакет на выполнение из Visual Studio нажав Start или клавишу F5:
Так же пакет можно выполнить, воспользовавшись командой из контекстного меню:
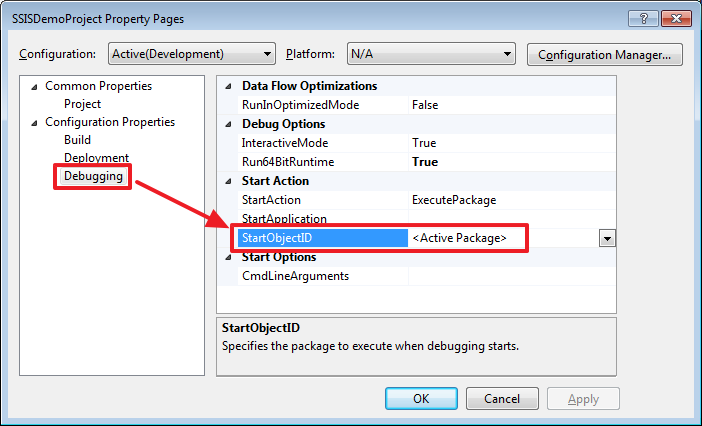
При помощи «Set as StartUp Object» можно задать пакет, который будет запускаться по нажатию на Start (F5).
Какой пакет будет запускаться при нажатии на Start (F5) можно переопределить в свойствах проекта:
Запустив проект мы должны увидеть следующую картину:

Пакет выполнился без ошибок, о чем говорит зеленый значок и текст в нижней части.
В случае наличия ошибок их можно будет увидеть вкладке Progress.
И убедимся, что данные были записаны в принимающую таблицу.
Перейдем в область «Control Flow» и создадим еще один компонент «Data Task Flow», который назовем «Load Products From Source B», протянем на него зеленную стрелку от «Load Products From Source A»:

Двойным щелчком зайдем в область «Data Flow» этого элемента и создадим «Source Assistant»:
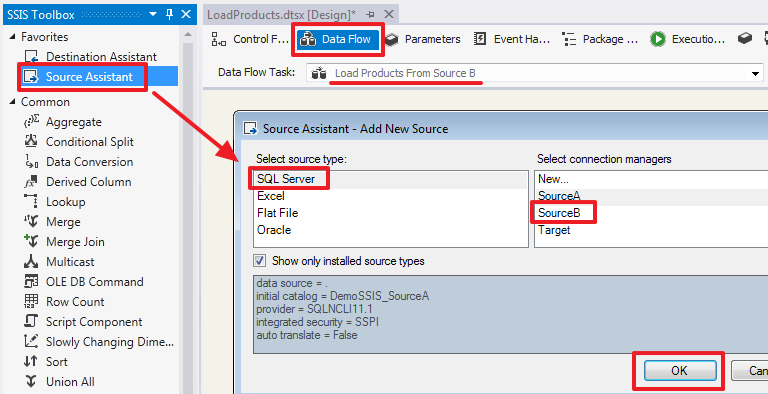
Дважды щелкнув на этом элементе, настроим его по-другому:

Выберем режим «SQL command» и пропишем следующий запрос:
Дальше сразу создадим компонент «Destination Assistant» и протянем на него синюю стрелку от «OLE DB Source»:

Двойным щелчком зайдем в редуктор этого элемента и настроим его:


Запустим проект на выполнение и убедимся, что данные с двух источников попали в таблицу в базе Target:

Дополнительно в контекстном меню стрелки можно активизировать «Data Viewer»:
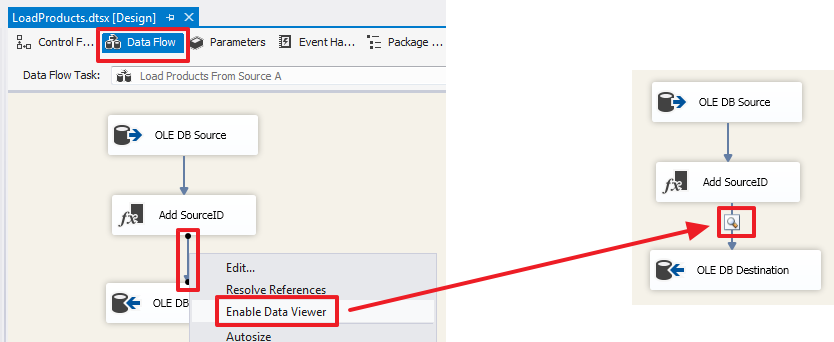
Теперь при запуске пакета на выполнение в этой точке будет сделана остановка и нам будут показаны данные этого потока:

Для продолжения выполнения пакета нужно нажать на кнопку со стрелкой или просто закрыть окно просмотра данных.
Для отключения этой функции в контекстном меню стрелки выбираем «Disable Date Viewer»:
Для первой части думаю этого будет достаточно.
В результате мы получим файл «C:SSISSSISDemoProjectinDevelopmentSSISDemoProject.ispac».
Рассмотрим каким образом делается развертывание этого проекта на SQL Server.
Создадим в трех демонстрационных базах новую таблицу ProductResidues, которая будет содержать информацию об остатках на каждый день:
USE DemoSSIS_SourceA
GO
CREATE TABLE ProductResidues(
ResidueDate date NOT NULL,
ProductID int NOT NULL,
ResidueAmount decimal(10,2) NOT NULL,
CONSTRAINT PK_ProductResidues PRIMARY KEY(ResidueDate,ProductID),
CONSTRAINT FK_ProductResidues_ProductID FOREIGN KEY(ProductID) REFERENCES Products(ID)
)
GO
USE DemoSSIS_SourceB
GO
CREATE TABLE ProductResidues(
ResidueDate date NOT NULL,
ProductID int NOT NULL,
ResidueAmount decimal(10,2) NOT NULL,
CONSTRAINT PK_ProductResidues PRIMARY KEY(ResidueDate,ProductID),
CONSTRAINT FK_ProductResidues_ProductID FOREIGN KEY(ProductID) REFERENCES Products(ID)
)
GO
USE DemoSSIS_Target
GO
CREATE TABLE ProductResidues(
ResidueDate date NOT NULL,
ProductID int NOT NULL,
ResidueAmount decimal(10,2) NOT NULL,
CONSTRAINT PK_ProductResidues PRIMARY KEY(ResidueDate,ProductID),
CONSTRAINT FK_ProductResidues_ProductID FOREIGN KEY(ProductID) REFERENCES Products(ID)
)
GO
И наполним таблицы в источниках тестовыми данными, поочередно выполнив на базах DemoSSIS_SourceA и DemoSSIS_SourceB следующий скрипт:
Допустим, что в таблице ProductResidues будет очень много строк, и чтобы каждый раз не перезагружать всю информацию и упростить процедуру интеграции, логику загрузки в таблицу ProductResidues в базе DemoSSIS_Target реализуем следующую:
Неудобство интеграции таблиц типа ProductResidues в том, что в ней нет полей, по которым можно было бы однозначно определить, когда появилась запись, в ней нет никакого идентификатора типа ID, нет ни поля типа UpdatedOn, которое содержало бы дату/время последнего обновления записи (т.е. зацепиться особо не за что), иначе бы мы, например, могли вычислить для каждого источника, по данным базы DemoSSIS_Target, последний ID или последнюю UpdatedOn и уже загружать данные из источников начиная от этих стартовых значений. К тому же не всегда есть возможность внести изменения в структуру источников, подстроив их под себя, т.к. это могут быть вообще чужие базы, к которым у нас нет полного доступа.
В нашем же случае еще допустим, что пользователи могут менять данные задним числом и могут вообще удалить некоторые ранее загруженные в базу DemoSSIS_Target строки из источников. Поэтому здесь обновление делается как-бы внахлёст, данные последней недели полностью перезаписываются. Здесь неделя берется условно, об этом минимальном сроке, например, мы могли бы условиться с заказчиком (он мог подтвердить, что данные обычно меняются максимум в течении недели). Конечно это не самый надежный способ, и иногда могут возникнуть расхождения, например, в том случае, когда пользователь поменял данные месячной давности и здесь стоит предусмотреть возможность перезагрузки данных начиная с более ранней даты, мы сделаем это при помощи параметра, в котором будем указывать нужное нам количество дней назад.
Создадим новый SSIS-пакет и назовем его «LoadResidues.dtsx».

В данном пакете, нажав на кнопку «Add Variable», создадим переменную LoadFromDate типа DateTime:

По умолчанию переменной присваивается текущее значение даты/времени, т.к. мы будем переопределять значение внутри пакета, нам это не важно.
Так же стоит обратить внимание на Expression – если прописать в этом поле выражение, то переменная будет работать как формула и мы не сможем изменять ее значение при помощи присваивания. При каждом обращении к такой переменной ее значение будет рассчитываться согласно указанному выражению.
Значения переменных можно задавать при помощи компонента «Expression Task». Давайте рассмотрим, как это делается. Создадим элемент «Expression Task»:

Двойным щелчком откроем редактор данного элемента:

Пропишем следующее выражение:
Здесь так же была применена двойная конвертация типа, чтобы избавиться от составляющей времени и оставить только дату.
Давайте так же посмотрим как можно отследить значение переменной во время выполнения пакета.
Создадим точку останова на элементе «Expression Task»:
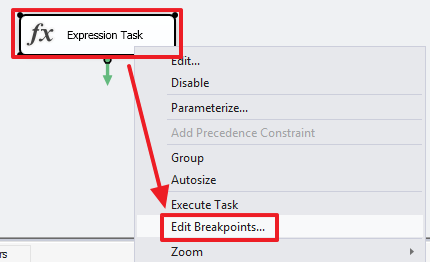
Укажем, что точка должна срабатывать по окончанию выполнения данного блока:
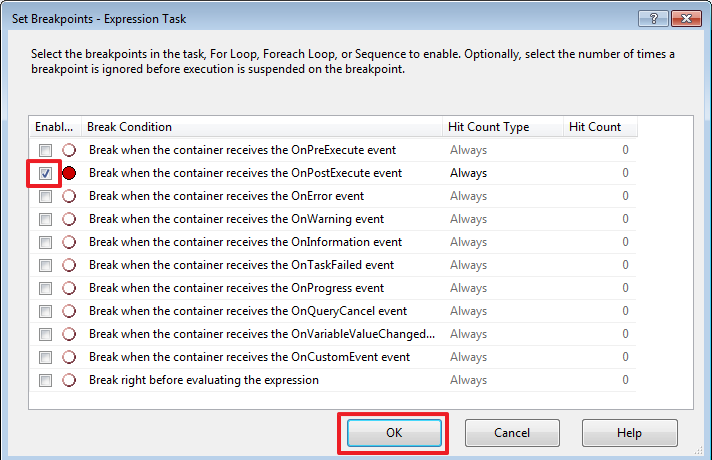
Запустим пакет на выполнение (F5) и после остановке в нашей точке, перейдем на вкладку «Locals»:
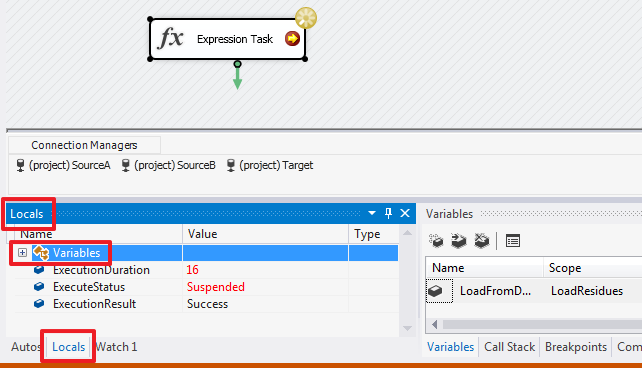
Раскроем список Variables и найдем в нем свою переменную:
Для интереса можем поменять выражение элементе «Expression Task» на следующее:
и также поэкспериментировать:

Точку останова убирается таким же образом каким и была установлена. Либо можно удалить сразу все точки останова, если их было несколько:
Создадим параметр, который будет отвечать за количество дней назад.
Параметр можно создать, как глобальный для всего проекта:

Так и локальный, внутри конкретного пакета:

Параметр может быть обязательный для задания – за это отвечает флаг Required. Если этот флаг установлен, то при создании задачи или при вызове пакета из другого пакета нужно будет определить входящее значение параметра (мы рассмотрим это далее).
В отличие от переменных значение параметров при помощи «Expression Task» менять нельзя.
Сохраним параметры и снова зайдем в редактор «Expression Task»:
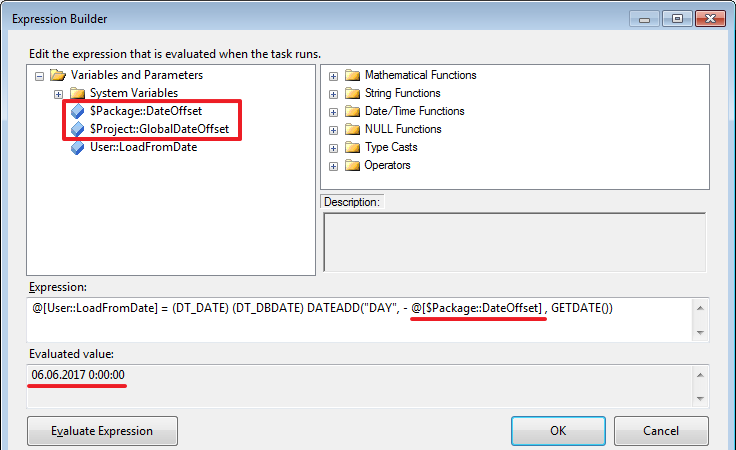
Для примера я поменял выражение на следующее:
Думаю, на этом суть параметров и переменных ясна, и мы можем продолжить.
После того как мы поигрались с «Expression Task» мы его удалим.
Создадим «Execute SQL Task»:


Пропишем в SQLStatement следующий запрос:
SELECT ISNULL(DATEADD(DAY,-?,MAX(ResidueDate)),’19000101′) FromDate
FROM ProductResidues
Т.к. данный запрос возвращает одну строку, установим ResultSet = «Single Row» и ниже на вкладке «Result Set» сохраним результат в значение переменной LoadFromDate.
На вкладке «Parameter Mapping» зададим значения параметров, которые в запросе обозначены знаком вопроса (?):

Параметры нумеруются, начиная с нуля.
Теперь на вкладке «Result Set» укажем в какую переменную нужно записать результат выполнения запроса:
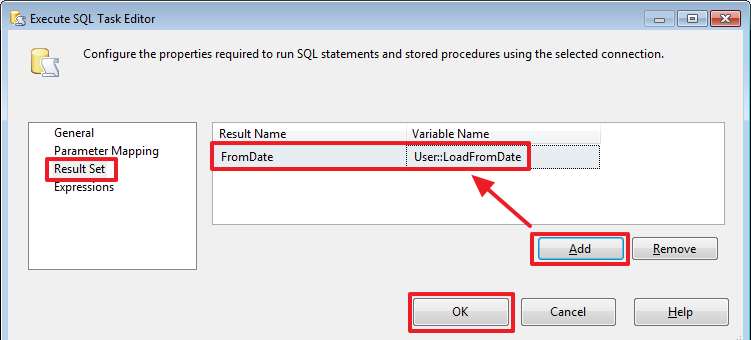
Здесь так же можем продебажить установив у этого компонента точку останова на «Break when the container receives the OnPostExecute event» и запустив пакет на выполнение:

Здесь я для удобства мониторинга значения переменной прописал название переменной в «Watch», чтобы не искать ее в блоке «Locals».
Как видим все верно в переменную LoadFromDate записалась дата «01.01.1900», т.к. строк в таблице ProductResidues на Target еще нет.
Переименую для наглядности «Execute SQL Task» в «Set LoadFromDate».
Создадим еще один элемент «Execute SQL Task» и назовем его «Delete Old Rows»:


SQLStatement содержит следующий запрос:
И зададим значение параметра на вкладке «Parameters Mapping»:
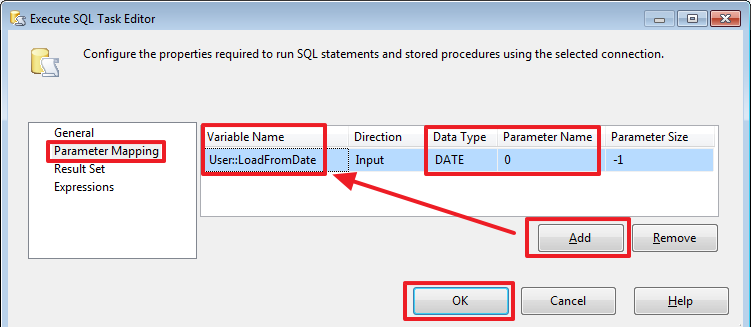
Все, удаление старых данных за указанный конечный период у нас реализовано.
Теперь сделаем часть отвечающую загрузку свежих данных. Для этого воспользуемся компонентом «Data Flow Task»:
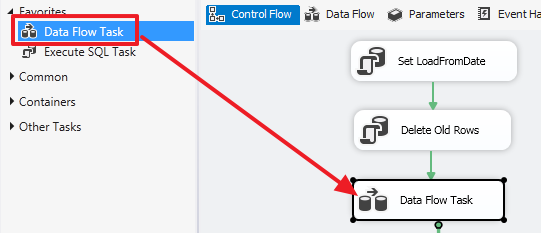
Зайдем в область данного компонента и создадим «Source Assistant»:



Для записи новых данных воспользуемся уже знакомым компонентом «Destination Assistant»:

Протянем стрелку от «Source Assistant» и настроим его:

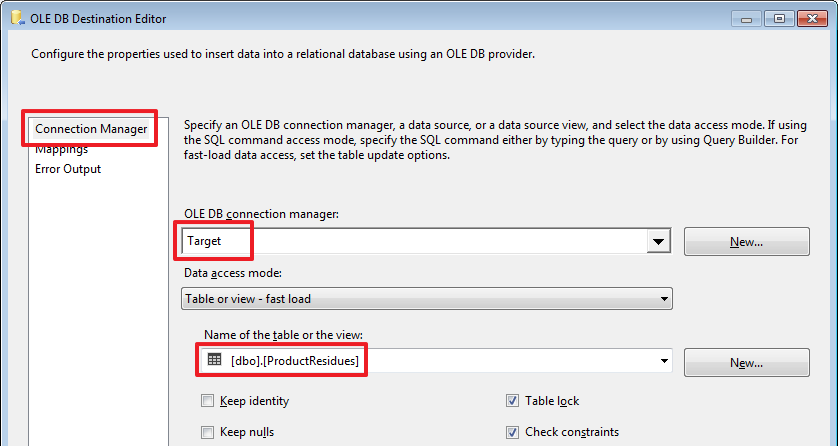

Все, пакет для переноса данных с источника SourceA у нас готов, можем запустить его на выполнение:
Запустим еще раз:
Как видим при повторном запуске удалились и залились только данные за указанный период. Ну вроде все работает так как мы и хотели. На всякий случай сверимся, что данные получателя по количеству равны данным источника:

Дойдя до сюда, я понял, что я допустил ошибку. Кто понял в чем дело, молодец!
Но может это и хорошо, т.к. пример получился не таким перегруженным.
Ошибка в том, что я забыл учесть, что при интеграции данных таблицы Products у нас в Target формируются свои идентификаторы (поле ID с флагом IDENTITY)!
Давайте переделаем, чтобы все было правильно. Ничего страшного повторим, зато лучше запомним.
Забежим чуть вперед и добавим в пакет еще один параметр, который назовем «SourceID»:

Перенастроим «Set LoadFromDate»:
В SQLStatement пропишем новый запрос с учетом SourceID:
SELECT ISNULL(DATEADD(DAY,-?,MAX(res. ResidueDate)),’19000101′) FromDate
FROM ProductResidues res
JOIN Products prod ON res. ProductID=prod. ID
WHERE prod. SourceID=?
Настроим второй параметр:
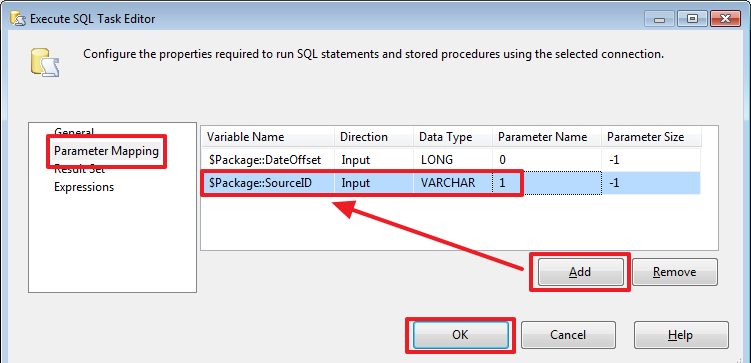
Теперь перенастроим «Delete Old Rows» аналогичным образом, чтобы учитывался SourceID:
В SQLStatement пропишем новый запрос с учетов SourceID:
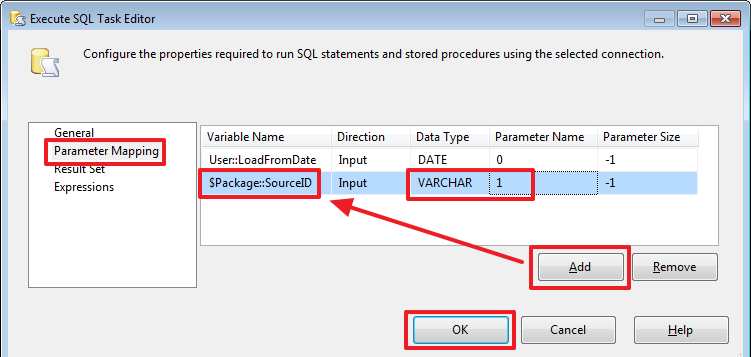
Теперь зайдем в «Data Flow Task», удалим цепочку и добавим «Derived Column»:


Здесь я намеренно оставил тип «Unicode string», а не сделал преобразование как в первой части. Давайте за одно рассмотрим компонент «Data Conversion»:

Теперь при помощи Lookup сделаем сопоставление и получим нужные нам идентификаторы продуктов:



Теперь протянем синюю стрелку от Lookup к «OLE DB Destination»:
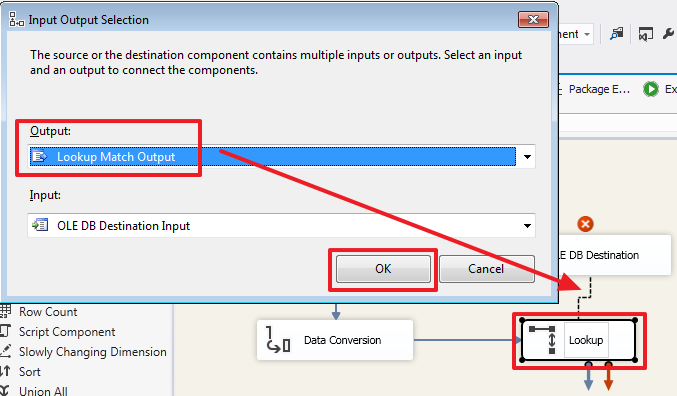
Выберем поток «Lookup Match Output»:

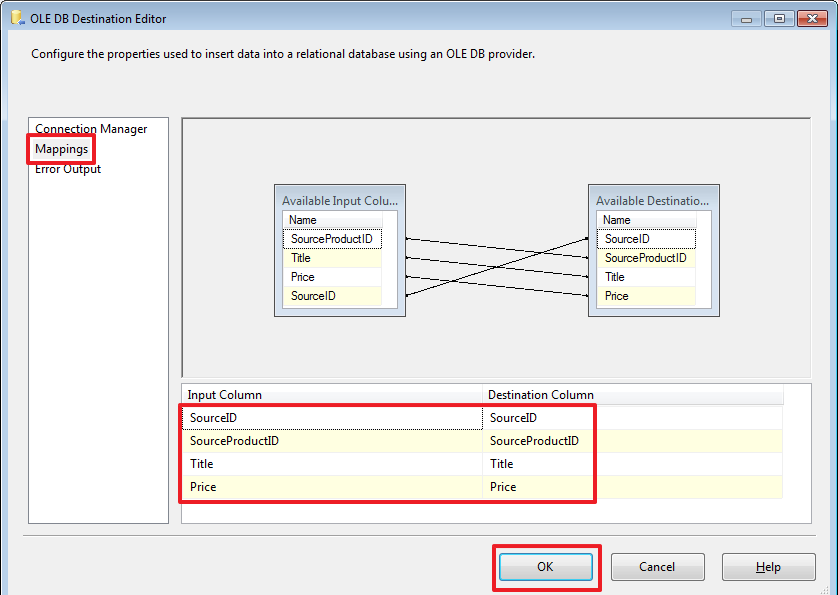
Настроим «OLE DB Destination», нужно перестроить Mappings:
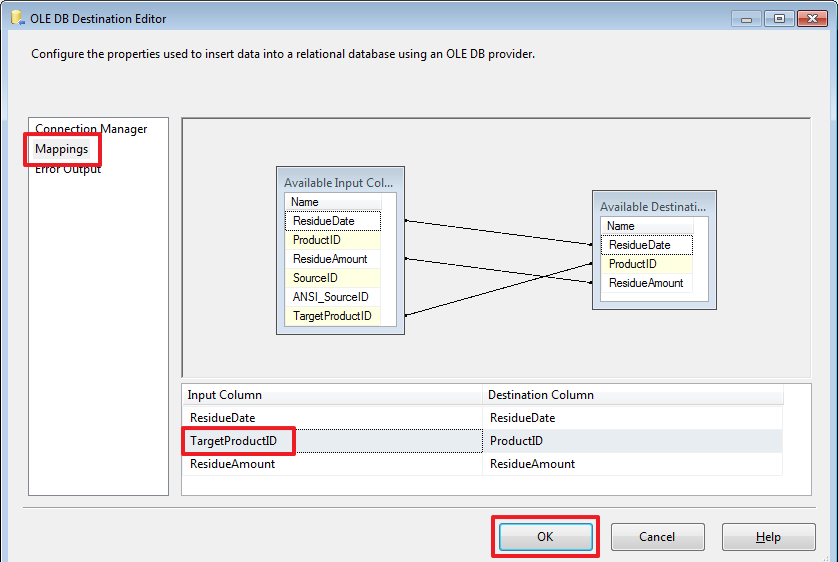
Все, сделаем очистку таблицы от неправильно загруженных данных:
TRUNCATE TABLE DemoSSIS_Target.dbo. ProductResidues

И еще раз:

Похоже на правду. Можете самостоятельно проверить правильно ли разнеслись идентификаторы продуктов.
Так как структура DemoSSIS_SourceA и DemoSSIS_SourceB одинакова и нам нужно сделать для DemoSSIS_SourceB, то же самое, то мы можем при создании задачи создать два шага для пакета «LoadResidues.dtsx», в первом шаге настроить подключение к базе DemoSSIS_SourceA, а на втором шаге DemoSSIS_SourceB.
Откомпилируем и передеплоим SSIS проект:

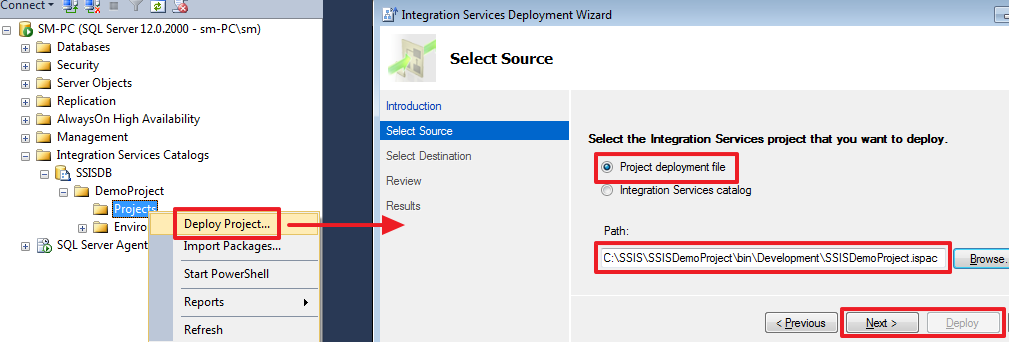
Давайте теперь создадим новое задание в SQL Agent:

На вкладке Steps создадим шаг 1 для загрузки продуктов:

Создадим шаг 2 для загрузки остатков из SourceA:
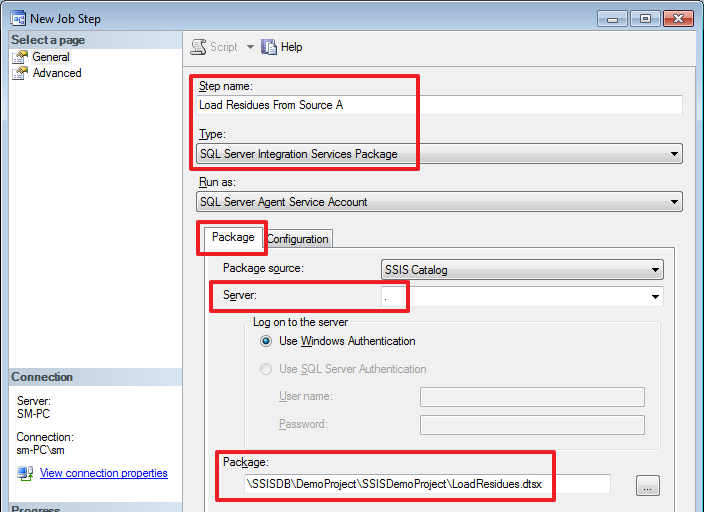
На вкладке Configuration можем увидеть наши параметры:

Здесь от нас требуют ввести SourceID, т.к. мы указали его как Required. Зададим его:

Данные вкладки «Connection Managers» изменять для этого шаге не будем.
Создадим шаг 3 для загрузки остатков из SourceB:

Зададим параметр SourceID:

И изменим данные соединения SourceA таким образом, чтобы оно ссылалось на базу DemoSSIS_SourceB:

В данном случае мне достаточно было изменить ConnectionString и InitialCatalog, теперь они указывают на DemoSSIS_SourceB.
В итоге мы должны получить следующее – три шага:
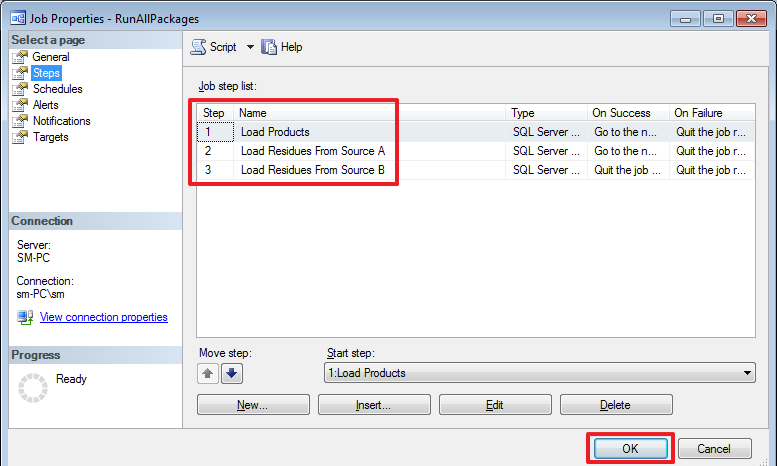
Запустим эту задачу на выполнение:

USE DemoSSIS_Target
GO
SELECT prod. SourceID,COUNT(*)
FROM ProductResidues res
JOIN Products prod ON res. ProductID=prod. ID
GROUP BY prod. SourceID
И убедимся, что все отработало как надо:
Теперь допустим, что базы DemoSSIS_SourceA и DemoSSIS_SourceB расположены на одном экземпляре SQL Server. Давайте переделаем «OLE DB Source»:


Теперь наш пакет в зависимости от значения параметра SourceID будет брать данные либо из SourceA, либо из SourceB.
Для теста можете изменить значение параметра SourceB на «B» и запустить проект на выполнение:
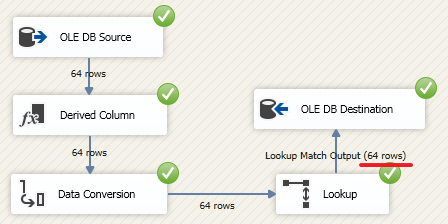
Давайте теперь создадим новый пакет «LoadAll.dtsx» и создадим в нем «Execute Package Task» (переименуем его в «Load Products»):

Настроим «Load Products»:
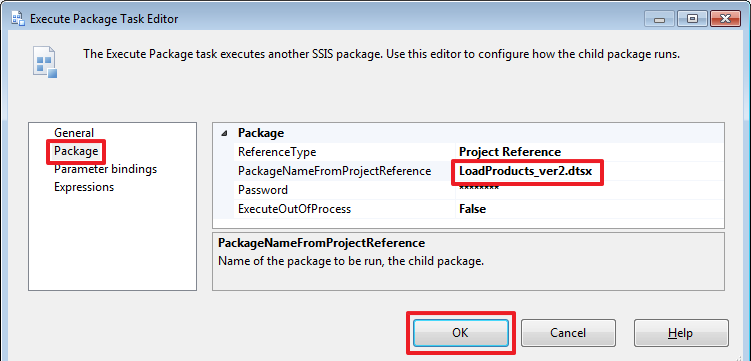
Создадим в новом пакете 2 параметра:

В области «Control Flow» создадим еще 2 компонента «Execute Package Task» которые назовем «Load Resudues A» и «Load Resudues B»:
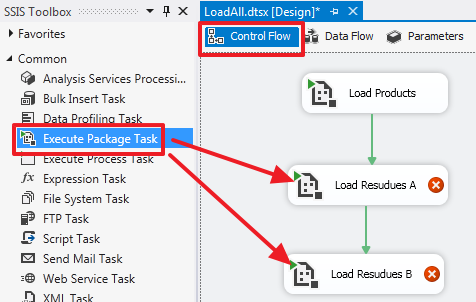
Настроим их задав у обоих название пакета «LoadResidues.dtsx»:

Зададим обязательный параметр SourceID для «Load Resudues A»:

Зададим обязательный параметр SourceID для «Load Resudues B»:
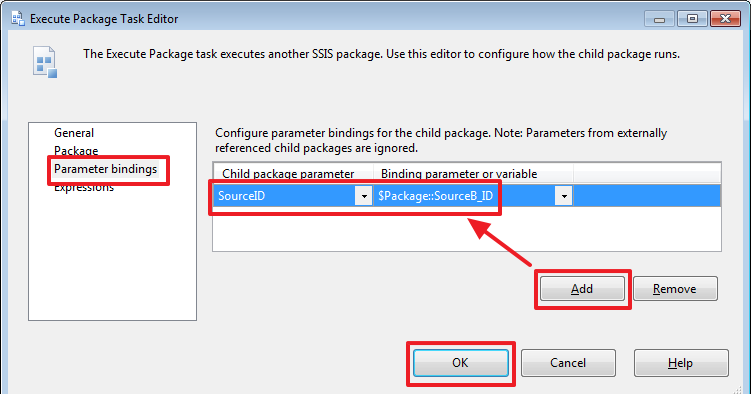
Обратите внимание, что у стрелок тоже есть свои свойства, например, мы можем поменять свойство Value на Completion, что будет означать, что следующий шаг будет выполнен даже в том случае если на шаге «Load Resudues A» произойдет ошибка:
Все, можем запустить пакет на выполнение:
Думаю, объяснять, что здесь произошло нет смысла.
Иногда параметры для конкретного пакета удобно хранить в вспомогательной таблице и считывать их оттуда в переменные пакета, например, используя для поиска глобальную переменную «System::PackageName». Для демонстрации, давайте переделаем наш пакет таким образом.
Создадим таблицу с параметрами:
USE DemoSSIS_Target
GO
CREATE TABLE IntegrationPackageParams(
PackageName nvarchar(128) NOT NULL,
DateOffset int NOT NULL,
CONSTRAINT PK_IntegrationPackageParams PRIMARY KEY(PackageName)
)
GO
INSERT IntegrationPackageParams(PackageName,DateOffset)VALUES
(N’LoadResidues’,7)
GO
Удалим параметр DateOffset из пакета «LoadResidues.dtsx»:

Создадим в пакете переменную DateOffset:

В область «Control Flow» добавим еще один элемент «Execute SQL Task» и переименуем его «Load Params»:

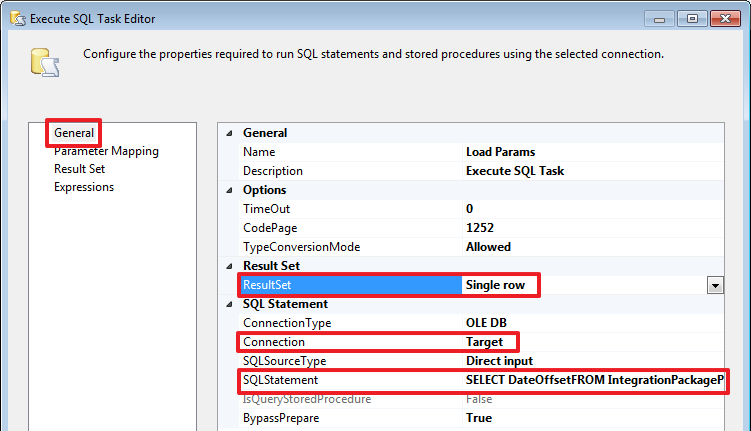
Запрос в SQLStatement пропишем следующий:
SELECT DateOffset
FROM IntegrationPackageParams
WHERE PackageName=?
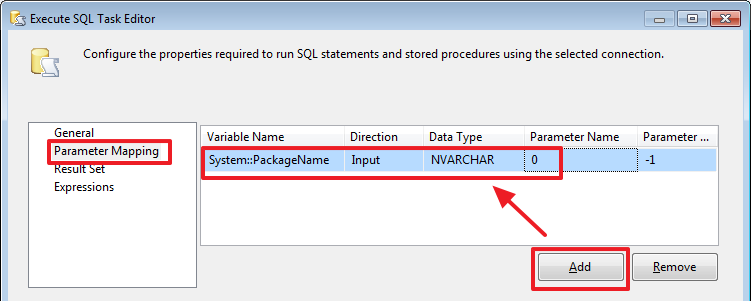
Настроим параметр запроса используя системную переменную «System::PackageName»:
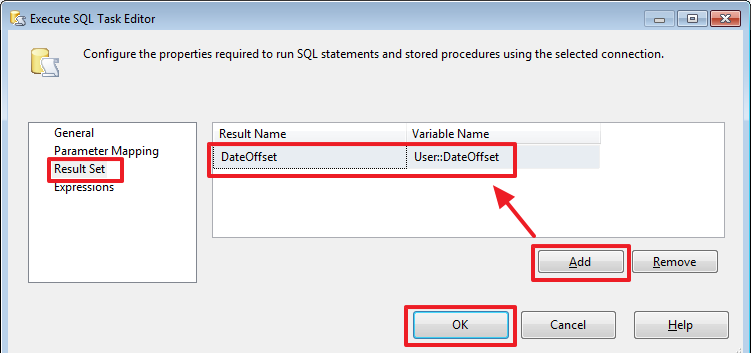
Осталось сбросить результат выполнения запроса в переменную:
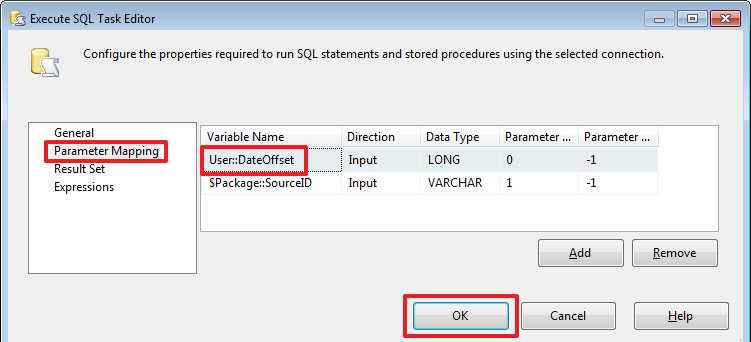
Теперь осталось перенастроить «Set LoadFromDate», чтобы в нем использовалась теперь переменная:
Все, можем тестировать новую версию пакета.
Вот мы и добрались до финиша. Мои поздравления!
Развертывание SSIS
Все последующие действия будем делать в SSMS.
Создание каталога SSISDB:
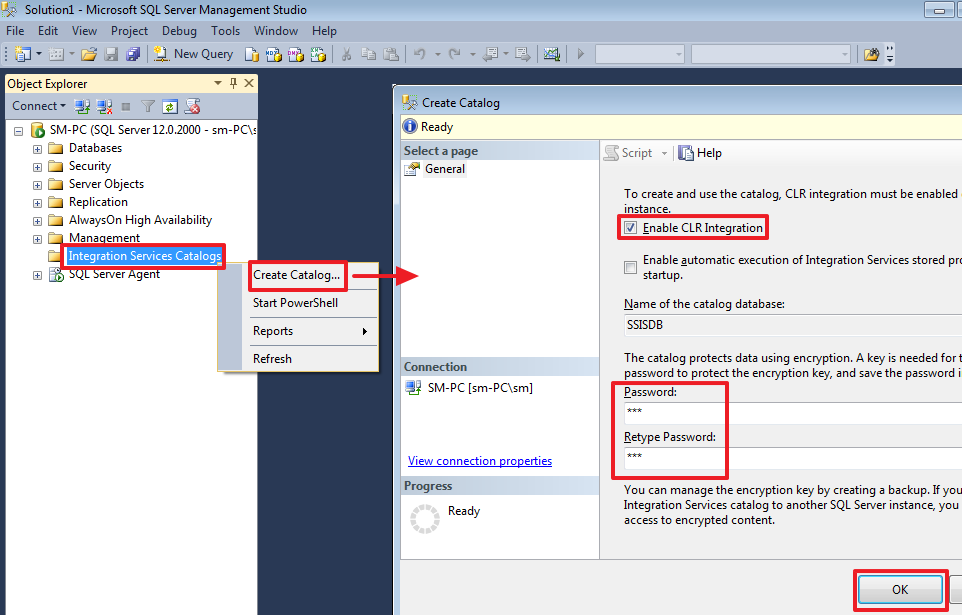
Здесь вводим любой пароль.
Теперь создаем папку, в которой будет располагаться наш проект:

Разворачиваем сам проект:




В завершении мы должны увидеть следующую картину:

После обновления (F5) мы увидим наш проект:
Заключение по второй части
В этой части мы рассмотрели каким образом можно делать синхронизацию небольших справочников. Здесь конечно не учитывается тот момент, что данные в источниках могут еще удаляться, но при необходимости вы сможете попробовать сделать это самостоятельно, т.к. при удалении иногда нужно учитывать дополнительные факторы, например, на удаляемую запись могут быть ссылки из других таблиц (в следующей части планируется это сделать).
Чтобы не нарушать ссылочную целостность, иногда запись в принимающей таблице удаляется логически, для этого, например, можно в эту таблицу добавить поле Deleted типа bit (флаг логического удаления) или DeletedOn типа datetime (дата/время логического удаления).
Порой на сервере, на котором располагается база Target делается вспомогательная промежуточная база (обычно ее называют Staging) и первым делом «сырые» данные из Source загружаются в нее. Так как теперь Target и Staging находятся на одном сервере, то вторым шагом мы можем легко написать SQL-запрос (например, используя SQL-конструкцию MERGE или запрос с применение конструкции JOIN), который оперирует с наборами обеих этих баз.
SSIS достаточно интересный инструмент, который на мой взгляд не помешает иметь в своем арсенале, так как в некоторых случаях он может сильно упростить процесс интеграции. Но конечно бывают ситуации, когда все взвесив, разумнее написать интеграцию прибегая к другим способам, например, использовать Linked Servers и писать процедуры на чистом TSQL или писать свою утилиту на каком-то другом языке программирования с применением всей мощи ООП и т.п.
Изучая материал проявляйте больше любопытства, например, щелкайте по вкладкам, которые я не показал, смотрите и анализируйте информацию на них, щелкайте по стрелкам, у них тоже есть свои свойства и настройки. Экспериментируйте, со всем что вам покажется интересным, не ленитесь делать свои небольшие тестовые примеры. Меняйте схему, так чтобы это приводило к исключениям, выбирайте более подходящие параметры у компонент пытаясь найти наиболее подходящий выход из сложившейся ситуации.
Спасибо за внимание! Удачи!
Заключение по третьей части
Уважаемые читатели, эта часть будет заключительной.
В данном цикле статей, я постарался продумать примеры таким образом, чтобы сделать их как можно короче и в свою очередь охватить как можно больше полезных и важных деталей.
Думаю, освоив это, далее вы уже без особого труда сможете освоить работу с остальными компонентами SSIS. В данных статьях я рассмотрел только самые важные компоненты (наиболее часто применяемые на моей практике), но зная только это вы уже можно сделать очень многое. По мере надобности изучайте самостоятельно другие компоненты, в первую очередь порекомендовал бы посмотреть следующее:
Доступного материала на эту тему очень много, используйте MSDN, Youtube и прочие источники.
Я не старался сделать подробный учебник (думаю, все это уже есть), а старался сделать такой материал, который позволит начинающим шаг за шагом создать все с самого нуля и делая все своими руками увидеть всю картину в целом, а после уже имея основу идти дальше самостоятельно. Очень надеюсь, что у меня это получилось и материал окажется полезен именно в таком ключе.
Я очень рад, что мне хватило сил осуществить задуманное и описать все так как я это хотел, даже получилось сделать большее, так как из-за допущенной в этой части ошибки возникли неожиданные повороты сюжета, но так я думаю, стало даже интересней. 😉
Заключение по первой части
В этой части я постарался дать обзорную картину, чтобы у читателя сразу сложилась в голове полная картина как все это выглядит и работает.
Я постарался описать все как можно подробнее, для того, чтобы обучающийся смог самостоятельно установить все необходимые инструменты и проработать материал шаг за шагом на практике, т.к. при самостоятельном изучении иметь рабочую среду это очень важный аспект.
На мой взгляд SSIS очень удобный и интуитивно понятный инструмент и многое в нем можно понять разбираясь самостоятельно. Это я говорю исходя из своего опыта, так как мне самому по большей части пришлось разбираться с SSIS самостоятельно и здесь я делюсь с вами своим опытом в данной области.
Надеюсь данный материал поможет многим сделать первые шаги в изучении данного инструмента и в дальнейшем применить свои знания в работе.
Хороших выходных! Удачи!




