

- Метод инкрементных изменений
- Структура файлов
- Хранение истории версий
- Автоматическое выполнение миграций
- Плюсы, минусы, выводы
- Liquibase и миграция данных
- Метод уподобления структуры БД исходному коду
- Пример реализации
- Выполнение миграций между версиями
- Как быть с изменениями данных?
- Feature-toggling в Spring Boot
- Инструменты и окружение
- Терминология
- Код проекта
- Зачем это нужно?
- Версия базы данных должна соответствовать версии приложения
- Так ли это просто?
- Готовые решения для версионной миграции БД
- Обновление сервиса и БД
- Метод идемпотентных изменений
- Что за птица такая — information_schema?
- Пример использования
- Настройки Spring Boot’а и Kubernetes deployment
Метод инкрементных изменений
Этот метод хорошо описан в статье «Versioning Databases – Change Scripts» все того же Скотта Аллена. Схожий подход также описан в статье «Managing SQL scripts and continuous integration» Майкла Бэйлона.
Структура файлов
Пример того, как в этом случае может выглядеть папка с файлами-миграциями:
В этом примере в папке хранятся все файлы, созданные при разработке версии 03. Впрочем, папка может быть и общей для всех версий приложения.
Фактически, в этом примере в имени файла содержится полный номер версии БД. То есть после выполнения файла-миграции с именем 0006.03.02.sql база данных обновится с состояния, соответствующего версии 03.02.0005, до версии 03.02.0006.
Хранение истории версий
Следующий шаг — добавление в базу данных специальной таблицы, в которой будет храниться история всех изменений в базе данных.
MigrationHistory
(
Id ,
MajorVersion
,
MinorVersion
,
FileNumber
,
Comment (255),
DateApplied ,(Id)
)
Это всего лишь пример того, как может выглядеть таблица. При необходимости, её можно как упростить, так и дополнить.
В файле Baseline.sql в эту таблицу нужно будет добавить первую запись:
MigrationHistory ( MajorVersion, MinorVersion, FileNumber, Comment, DateApplied )
( , , , , NOW() )
После выполнения каждого файла-миграции в эту таблицу будет заноситься запись со всеми данными о миграции.
Текущую версию БД можно будет получить из записи с максимальной датой.
Автоматическое выполнение миграций
Завершающий штрих в этом подходе — программа/скрипт, который будет обновлять БД с текущей версии до последней.
Выполнять миграцию БД автоматически довольно просто, т.к. номер последней выполненной миграции можно получить из таблицы MigrationHistory, а после этого остается только применить все файлы с бо́льшими номерами. Сортировать файлы можно по номеру, поэтому с порядком выполнения миграций проблем не будет.
На такой скрипт также возлагается задача добавления записей о выполненных миграциях в таблицу MigrationHistory.
В качестве дополнительных удобств, такой скрипт может уметь создавать текущую версию БД с нуля, сначала накатывая на БД основание, а затем выполняя стандартную операцию по миграции до последней версии.
Плюсы, минусы, выводы
Этот метод в различных формах довольно широко распространен. К тому же, он легко поддается упрощению и модификации под нужды проекта.
В интернете можно найти готовые варианты скриптов по инкрементному выполнению миграций и встроить в свой проект.
Liquibase и миграция данных
Теперь перейдем к скриптам обновления БД. И для обновления схемы, и для обновления данных, мы будем использовать Liquibase. Иногда используют подход, при котором в Liquibase хранят только DDL, тогда скрипты миграции запускаются отдельно. Я не вижу особых резонов выносить это. Бывают миграции данных, продиктованные бизнес-потребностями — импорт пользователей из сторонней системы, например. Такие скрипты действительно не должны попадать в Liquibase, потому что они актуальны для конкретного стенда, могут содержать чувствительные данные и т.п. Но в нашем случае выполняется техническая миграция, связанная с изменением типа данных. Еще могут быть ситуации, когда миграция данных запускается через какой-то CI/CD-инструмент, который не ожидает, что операция может идти часами. Но в целом, если мы можем обновлять базу из единого места, почему бы это не делать?
Также Spring Boot позволяет выполнять миграции вместе со стартом приложения, но я не рекомендую так делать. Хотя у этого подхода есть два плюса:
Но также у него есть и минусы:
Метод уподобления структуры БД исходному коду
Отдельных статей, посвященных этому подходу, я, к сожалению, не нашел. Буду благодарен за ссылки на существующие статьи, если таковые имеются. U PD: В своей статье Absent рассказывает о своем опыте реализации схожего подхода при помощи самописной diff-утилиты.
Основная идея этого метода отражена в заголовке: структура БД — такой же исходный код, как код PHP, C# или HTML. Следовательно, вместо того, чтобы хранить в репозитории кода файлы-миграции (с запросами, изменяющими структуру БД), нужно хранить только актуальную структуру базы данных — в декларативной форме.
Пример реализации
Для простоты примера будем считать, что в каждой ревизии репозитория всегда будет только один SQL-файл: CreateDatabase.sql. В скобках замечу, что в аналогии с исходным кодом можно пойти еще дальше и хранить структуру каждого объекта БД в отдельном файле. Также, структуру можно хранить в виде XML или других форматов, которые поддерживаются вашей СУБД.
В файле CreateDatabase.sql будут храниться команды CREATE TABLE, CREATE PROCEDURE, и т.д., которые создают всю базу данных с нуля. При необходимости изменений структуры таблиц, эти изменения вносятся непосредственно в существующие DDL-запросы создания таблиц. То же касается изменений в хранимых процедурах, триггерах, и т.д.
К примеру, в текущей версии репозитория уже есть таблица myTable, и в файле CreateDatabase.sql она выглядит следующим образом:
myTable
(
id
,
myField (255) ,
(id)
);
Если вам нужно добавить в эту таблицу новое поле, вы просто добавляете его в имеющийся DDL-запрос:
myTable
(
id
,
myField (255) ,
newfield INT
NOT NULL,
(id)
);
После этого измененный sql-файл сабмиттится в репозиторий кода.
Выполнение миграций между версиями
В этом методе процедура обновления базы данных до более новой версии не так прямолинейна, как в других методах. Поскольку для каждой версии хранится только декларативное описание структуры, для каждой миграции придется генерировать разницу в виде ALTER-, DROP — и CREATE-запросов. В этом вам помогут автоматические diff-утилиты, такие, как Schema Synchronization Tool, входящая в состав SQLyog, TOAD, доступный для многих СУБД, Dklab_pgmigrator для PostgreSQL от DmitryKoterov, а также, SQL Comparison SDK от RedGate.
Чтобы выполнить миграцию с одной версии БД до другой, вам придется восстановить на двух временных БД структуру исходной и конечной версий, и затем сгенерировать миграционный скрипт. Впрочем, эта процедура может быть автоматизирована и много времени занимать не должна.
Как быть с изменениями данных?
Время от времени, при обновлении версии базы данных на продакшн-серверах, нужно обновлять не только структуру БД, но и хранящиеся в ней данные. В качестве примера можно привести перенос данных из таблицы со старой структурой в новые таблицы — в целях нормализации. Поскольку данные на продакшн-серверах уже существуют и используются, недостаточно просто создать новые таблицы и удалить старые, нужно еще и перенести имеющиеся данные.
В предыдущих методах, в контексте хранения и выполнения миграций, данные мало чем отличались от структуры БД. Но в данном методе изменения в данных стоят особняком, ведь хранить их в репозитории кода в декларативной форме невозможно: данные на всех серверах разные. А автоматически сгенерировать такие запросы для изменения данных также невозможно: это требует человеческого вмешательства.
У этой проблемы есть несколько более или менее приемлемых решений:
Удобно наблюдать изменения в структуре между версиями при помощи средств системы контроля версий;
Как и любой исходный код, структуру БД удобно комментировать;
Для того, чтобы с нуля создать чистую базу данных последней версии, нужно выполнить всего лишь один файл;
Скрипты-миграции более надежны, чем в других методах, так как генерируются автоматически;
Мигрировать с новых версий на старые почти так же просто, как со старых на новые (проблемы могут возникнуть только с пресловутыми изменениями данных);
В случае слияния двух веток репозитория, merge структуры БД осуществляется проще, чем при использовании других подходов;
Изменения данных придется хранить отдельно, и затем вручную вставлять в сгенерированные скрипты-миграции;
Вручную выполнять миграции очень неудобно, необходимы автоматизированные средства.
Этот метод имеет много позитивных качеств. Если вас не страшат описанные проблемы с изменениями данных, и если обновления продакшн-серверов случаются редко, рекомендую использовать именно этот метод.
Feature-toggling в Spring Boot
Мы хотим написать одно приложение, которое в зависимости от настроек, применяемых на лету, пишет и читает данные по-разному. Для этого мы используем Togglz, библиотеку feature-toggling’а для Java (так же можно взять FF4J). Для реализации логики нам потребуется 2 флага:
Если посмотреть выше описание подхода с реализацией логики на стороне приложения, то случай, когда обе фичи выключены — v. 1.1.0, когда вторая включена — v. 1.1.1, когда обе включены — v. 1.1.2. F EATURE_WRITE_POST_STATUS_ONLY не должен включаться без включенного FEATURE_READ_POST_STATUS.
Фича-флаги можно использовать как условия для if’ов в логике работы приложения, они достаточно просто инъектятся в бины. Но мы будем использовать другой подход — будем подменять сами бины в зависимости от включения / выключения фичи. Поэтому сначала адаптируем архитектуру приложения:
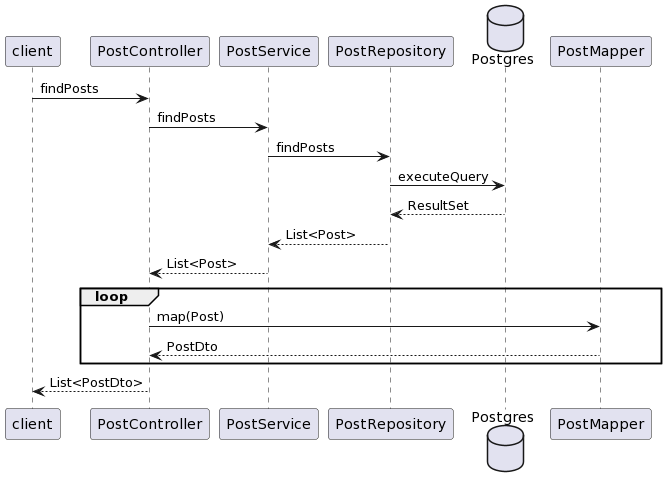
Первоначальная диаграмма последовательности для сервиса
Нам требуется сохранить API сервиса, и для реализации новой логики такая архитектура нам неудобна. Переложим ответственность за маппинг модели в DTO на сервисный слой и разделим сервис на операции чтения / записи. Тогда новая архитектура будет выглядеть как-то так:
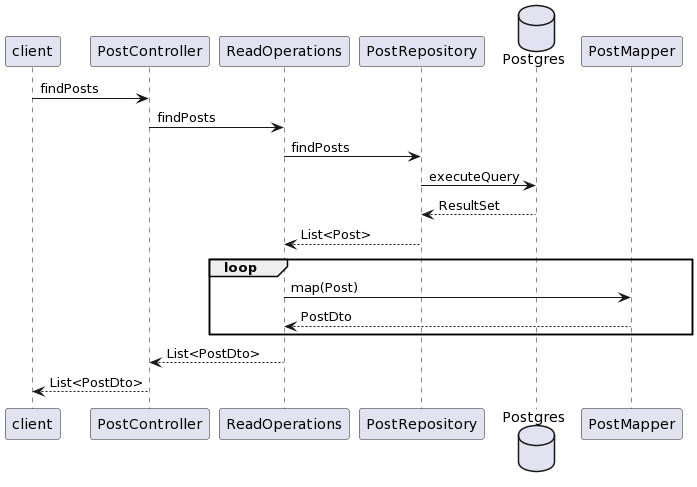
Целевая диаграмма последовательности для сервиса
Таким образом, нам нужно 2 реализации ReadOperations, каждая из которых ссылается на свой репозиторий и свой маппер, и 2 реализации WriteOperations, использующих те же самые репозитории и мапперы, что и ReadOperations. Такое разделение на операции чтения и записи хоть и выглядит некрасиво с точки зрения предметной области, но бывает полезно еще и для масштабирования приложения с репликами БД, работающими только на чтение — тогда у ReadOperations будет свой DataSource, настроенный на readonly-реплики.
Сделаем бины-операции RequestScope и будем создавать их через кастомную фабрику, которая создает нужный вариант бина в зависимости от состояния feature flag’а:
Для конфигурирования Togglz мы объявляем enum с нашими флагами, создаем для него EnumBasedFeatureProvider, и говорим, что состояние флагов будет хранится в БД. Причем, чтобы на каждый запрос не было бы лишнего обращения к БД, мы используем CachingStateRepository с TTL 5 секунд. Создание бонов-операций вынесено в отдельный Configuration-класс. Он смотрит на состояние флага через FeatureManager и в зависимости от этого создает нужную версию бина. Переключение feature-флагов будет происходить через actuator-endpoint, который идет в комплекте с togglz-starter’ом (для этого надо явно включить его в application.properties: management.endpoints.web.exposure.include = health,togglz).
Инструменты и окружение
Я использовал максимально простой вариант для всех этих инструментов. Postgres разворачивался в качестве Docker-контейнера на рабочей машине, без всяких кластеров. В качестве Kubernetes я использовал версию, поставляемую с Docker Desktop. Liquibase запускался как gradle task в основном проекте приложения.
Функционально сервис позволяет создавать, вычитывать и обновлять сообщения. Каждое сообщение имеет 5 основных атрибутов — ID, тема, текст, автор и признак, опубликовано оно или нет.
Сообщение создается опубликованным, но впоследствии его можно скрыть. Можно получать сообщения по ID, либо искать последние сообщения определенного автора (в этом случае есть возможность получить только опубликованные сообщения или вообще все).
Сервис поднят в Kubernetes, работают 2 реплики.
Сценарий нагрузки JMeter представлен генераторами трех видов:
Когда я запускаю этот сервис и нагрузочный скрипт на своей машине, генерируется нагрузка в 90 tps на создание сообщений, 600 tps на чтение и 13 tps на обновление.
Не используйте такие типы тестов при нормальном НТ
Подобные сценарии не должны использоваться для настоящего нагрузочного тестирования. Здесь используется мало потоков, которые выполняют столько действий, сколько успеют, без какой‑то паузы. В результате такой профиль очень гуманен к сервису — сервис запнулся, 56 потоков встали в ожидание ответа и все. Более реалистичный сценарий — тысячи потоков с паузами между запросами и коротким временем ожидания ответа от сервиса. Если сервис запнулся на длительное время, то быстро растет очередь необработанных соединений. Как сервис поведет себя в этом случае — очень важный фактор поведения приложения под нагрузкой.
Терминология
База данных — совокупность всех объектов БД (таблиц, процедур, триггеров и т.д.), статических данных (неизменяемых данных, хранящихся в lookup-таблицах) и пользовательских данных (которые изменяются в процессе работы с приложением).
Структура базы данных — совокупность всех объектов БД и статических данных. Пользовательские данные в понятие структуры БД не входят.
Версия базы данных — определенное состояние структуры базы данных. Обычно у версии есть номер, связанный с номером версии приложения.
Миграция, в данном контексте, — обновление структуры базы данных от одной версии до другой (обычно более новой).
Код проекта
Полный код доступен на GitHub
Зачем это нужно?
Разработчики, которые уже сталкивались с проблемой рассинхронизации версий БД и приложения, могут пропустить этот раздел. Здесь я напомню, почему нужно соблюдать паритет версий приложения и базы данных и какая общая проблема при этом возникает.
Версия базы данных должна соответствовать версии приложения
Итак, представьте себе следующую ситуацию: команда из нескольких программистов разрабатывает приложение, которое активно использует базу данных. Время от времени приложение поставляется в продакшн — например, это веб-сайт, который деплоится на веб-сервер.
Любому программисту в процессе написания кода приложения может понадобиться изменить структуру базы данных, а также, сами данные, которые в ней хранятся. Приведу простой пример: допустим, есть необнуляемое (not nullable) строковое поле в одной из таблиц. В этом поле не всегда есть данные, и в этом случае там хранится пустая строка. В какой-то момент вы решили, что хранить пустые строки — семантически неправильно в некоторых случаях (см. 1, 2), а правильно — хранить NULL’ы. Для того, чтобы это реализовать, понадобятся следующие действия:
1. Изменить тип поля на nullable:
myTable myField myField (255) ;
2. Так как в этой таблице на продакшн БД уже наверняка есть пустые строки, вы принимаете волевое решение и трактуете их как отсутствие информации. Следовательно, нужно будет заменить их на NULL:
myTable myField = myField = ;
3. Изменить код приложения так, чтобы при получении из БД данных, хранящихся в этом поле, он адекватно реагировал на NULL’ы. Записывать в это поле тоже теперь нужно NULL’ы вместо пустых строк.
Из пункта 3 можно видеть, что приложение и база данных — неразрывные части одного целого. Это означает, что при поставке новой версии приложения в продакшн, нужно обязательно обновлять и версию базы данных, иначе приложение попросту не сможет правильно работать. В данном примере, если до новой версии будет обновлено только приложение, то в какой-то момент произойдет вставка NULL в необнуляемое поле, а это очевидная ошибка.
Таким образом, обновление версии приложения требует корректной версионной миграции базы данных.
Так ли это просто?
Осознав, что паритет версий БД и приложения необходим, вам нужно удостовериться, что миграции БД до нужной версии всегда будут выполняться правильно. Но в чём здесь проблема? Ведь, на первый взгляд, сложного здесь ничего нет!
Таким образом, можно сделать вывод, что в процессе версионной миграции все запросы должны выполняться только один раз и, к тому же, в правильной последовательности. Последовательность важна потому, что одни изменения могут зависеть от других (как в примере с обнуляемым полем).
Готовые решения для версионной миграции БД
Описанные выше методы могут использоваться без сторонних решений, однако существуют и готовые к использованию продукты, каждый со своей идеологией и оригинальным подходом, достойные отдельной статьи. При выборе решения версионной миграции, обязательно рассмотрите и такие продукты.
Некоторые из них рассмотрены в недавней статье «Подходы для версионирования баз данных» Дениса Гладких.
Ниже перечислена лишь малая часть готовых к использованию систем версионной миграции:
Обновление сервиса и БД
Итак, теперь соберем все это в единое целое и проверим, как это все будет работать под нагрузкой.
В первом прогоне этого сценария после второго шага были выявлены немногочисленные ошибки при создании новой записи cached plan must not change result type . Это было довольно любопытно, поскольку мы вроде как вставляем данные, откуда там взялась ошибка, характерная для чтения? Причина в том, как Spring Data JDBC и драйвер PostgreSQL работают с автогенерацией ключей: результат эквивалентен дописыванию в конце запроса RETURNING *. Поэтому при добавлении / удалении / изменении типа столбцов случается такая ошибка при insert-запросах в уже открытых транзакциях. Что интересно, Spring Data JDBC содержит логику, которая может фактически дописывать RETURNING id, что решило бы эту проблему. Но это поведение определяется соответствующей настройкой диалекта БД, которая для PostgreSQL отключена. Для решения можно воспользоваться пользовательским запросом в репозитории:
После этой доработки повторяем тест. Вместо восстановления из бэкапа, можем воспользоваться скриптами отката до 1.0.x, заодно их и проверим (в описанном процессе отката под нагрузкой будут ошибки; если нужно откатить аккуратнее, то нужно делать больше промежуточных шагов по аналогии с процедурой обновления. Но такой откат на несколько версий назад — это не плановая процедура, прерывание сервиса на какое-то время обычно допустимо в этом случае):
Потом накатим исправленную версию приложения 1.0 и повторим выкатку версии 1.1 (с теми же исправлениями) под нагрузкой.
В результате обновление модели данных прошло успешно, нам удалось не получить ни одной ошибки. По влиянию обновления сервиса на клиентов можно сказать, что оно, конечно, есть, но весьма незначительное (по сути, единственное явное влияние видно в моменте переключения сервиса на новую версию — всплеск выше 250 мс в первой четверти графика). Максимальное время отклика за время прохождения теста составило 1800 мс.
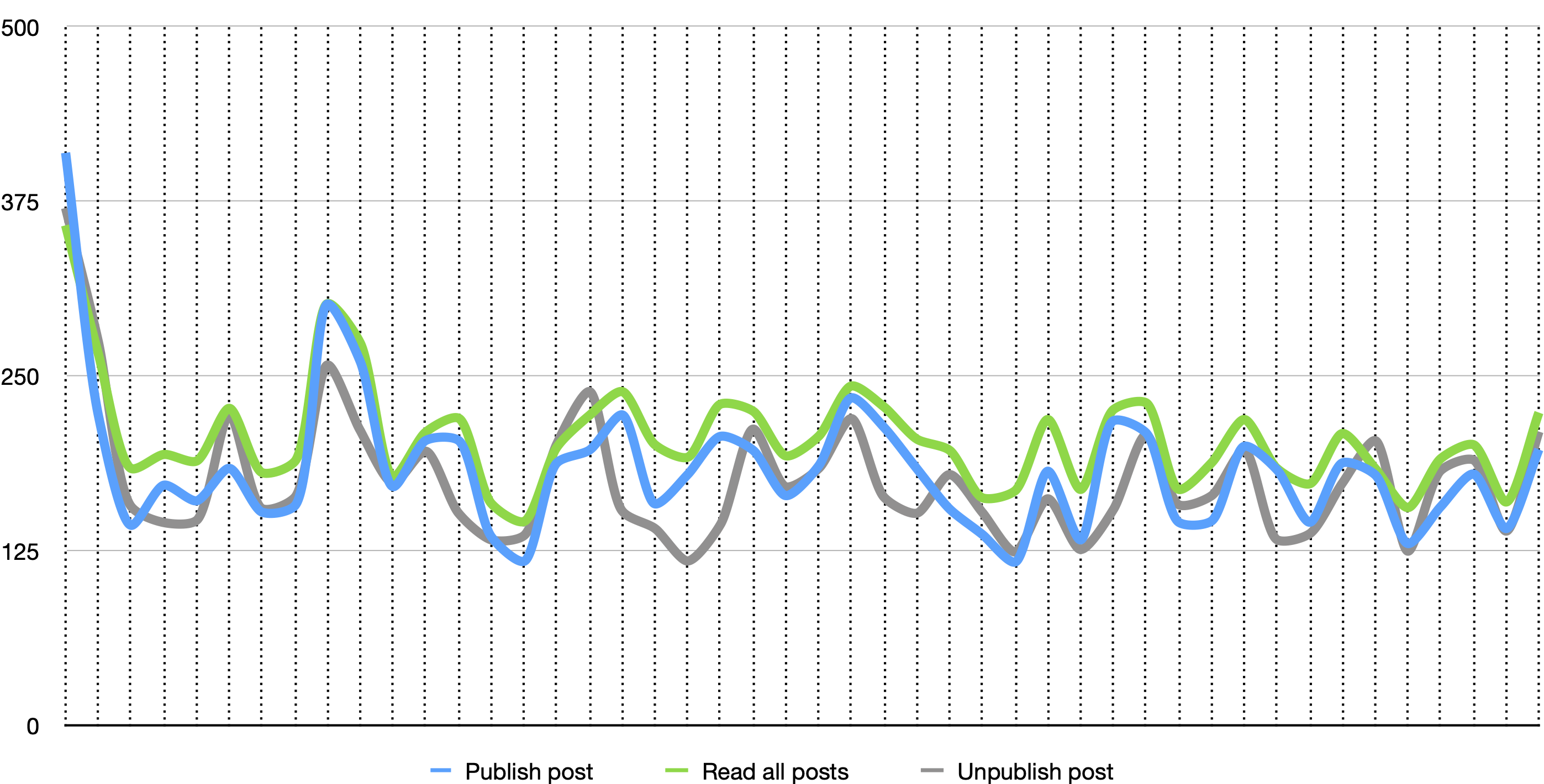
Времена отклика, мс (99-й персентиль)
Пару слов относительно разброса времен отклика, особенно по сравнению с предыдущими графиками — не надо их сравнивать. Первые 2 графика относятся к одному и тому же тесту, на схожем наполнении БД и при примерно равной длительности. Их корректно сопоставлять между собой. Последний график — совсем другой тест, на большем количестве данных, для графика берется 99-й персентиль и используется больший период для агрегации данных и т.п. В целом, графики приведены скорее для иллюстрации — когда на одной машине выполняется и сервис, и миграция, и скрипты нагрузки, доверия к абсолютным цифрам не должно быть.
Метод идемпотентных изменений
Этот метод описан в статье «Bulletproof Sql Change Scripts Using INFORMATION_SCHEMA Views» Фила Хэка. Описание схожего подхода также изложено в ответе на этот вопрос на StackOverflow.
Под идемпотентностью понимается свойство объекта оставаться неизменным при повторной попытке его изменить.
В тему вспоминается смешная сцена из «Друзей» 🙂
Основная идея этого подхода — написание миграционных файлов таким образом, чтобы их можно было выполнить на базе данных больше одного раза. При первой попытке выполнить любую из SQL-команд, изменения будут применены; при всех последующих попытках ничего не произойдет.
Эту идею проще всего уяснить на примере. Допустим, вам нужно добавить в БД новую таблицу. Если вы хотите, чтобы в том случае, если она уже существует, при выполнении запроса не возникло ошибки, — в MySQL для этих целей есть краткий синтаксис:
IF NOT EXISTS myTable
(
id
,
myField (255) ,
(id)
);
Благодаря ключевой фразе IF NOT EXISTS, MySQL попытается создать таблицу только в том случае, если таблицы с таким именем еще не существует. Однако такой синтаксис доступен не во всех СУБД; к тому же, даже в MySQL его можно использовать не для всех команд. Поэтому рассмотрим более универсальный способ:
IF NOT EXISTS
(
*
information_schema.tables
table_name =
table_schema =
)
myTable
(
id
,
myField (255) ,
(id)
);
;
В последнем примере роль параметра условного выражения играет запрос, который проверяет, существует ли таблица myTable в базе данных с именем myDb. И только в том случае, если таблица отсутствует, произойдет, собственно, ее создание. Таким образом, приведенный запрос является идемпотентным.
Стоит отметить, что в MySQL по какой-то причине запрещено выполнять DDL-запросы внутри условных выражений. Но этот запрет легко обойти — достаточно включить все подобные запросы в тело хранимой процедуры:
DELIMITER $ sp_tmp()
(
)
— Запрос, изменяющий структуру БД.
;;
$ sp_tmp(); sp_tmp;
Что за птица такая — information_schema?
Полную информацию о структуре базы данных можно получить из специальных системных таблиц, находящихся в базе данных с именем information_schema. Эта база данных и ее таблицы — часть стандарта SQL-92, поэтому этот способ можно использовать на любой из современных СУБД. В предыдущем примере используется таблица information_schema.tables, в которой хранятся данные о всех таблицах. Подобным образом можно проверять существование и метаданные полей таблиц, хранимых процедур, триггеров, схем, и, фактически, любых других объектов структуры базы данных.
Полный перечень таблиц с подробной информацией об их предназначении можно посмотреть в тексте стандарта. Краткий перечень можно увидеть в уже упоминавшейся выше статье Фила Хэка. Но самый простой способ, конечно же, — просто открыть эту базу данных на любом рабочем сервере БД и посмотреть, как она устроена.
Пример использования
Итак, вы знаете, как создавать идемпотентные SQL-запросы. Теперь рассмотрим, как этот подход можно использовать на практике.
Пример того, как в этом случае может выглядеть папка с sql-файлами:
В этом примере для каждой минорной версии базы данных создается отдельная папка. При создании каждой новой папки генерируется основание и записывается в Baseline.sql. Затем в процессе разработки в файл Changes.sql записываются все необходимые изменения в виде идемпотентных запросов.
Предположим, в процессе разработки в разное время программистам понадобились следующие изменения в БД:
a) создать таблицу myTable;
b) добавить в нее поле newfield;
c) добавить в таблицу myTable какие-то данные.
Все три изменения написаны так, чтобы не выполняться повторно. В результате, в каком бы из промежуточных состояний не находилась база данных, при выполнении файла Changes.sql всегда будет выполнена миграция до самой последней версии.
К примеру, один из разработчиков создал на своей локальной копии БД таблицу myTable, записал изменение a) в хранящийся в общем репозитории кода файл Changes.sql, и на какое-то время забыл о нём. Теперь, если он выполнит этот файл на своей локальной БД, изменение a) будет проигнорировано, а изменения b) и c) будут применены.
Очень удобное выполнение миграций с любой промежуточной версии до последней — нужно всего лишь выполнить на базе данных один файл (Changes.sql);
Потенциально возможны ситуации, в которых будут теряться данные, за этим придется следить. Примером может служить удаление таблицы, и затем создание другой таблицы с тем же именем. Если при удалении проверять только имя, то обе операции (удаление и создание) будут происходить каждый раз при выполнении скрипта, несмотря на то, что когда-то уже выполнялись;
Для того, чтобы изменения были идемпотентными, нужно потратить больше времени (и кода) на их написание.
Благодаря тому, что обновить базу данных до последней версии очень просто, и делать это можно вручную, этот метод показывает себя в выгодном свете в том случае, если у вас много продакшн-серверов и их нужно часто обновлять.
Настройки Spring Boot’а и Kubernetes deployment
Давайте для начала просто обновим версию приложения, не трогая его код — просто сделаем еще одну версию докер-образа и скажем сервису ее использовать. Исходное состояние: Spring Boot сервис с настройками по умолчанию, K8S deployment содержит только конфигурацию RollingUpdate (не задано никаких проб):
Запускаем нагрузку, ждем пару минут, обновляем версию приложения:
$ kubectl set image deployment/zero-dt-deployment zero-dt-app=zero-dt-app:1.0.1
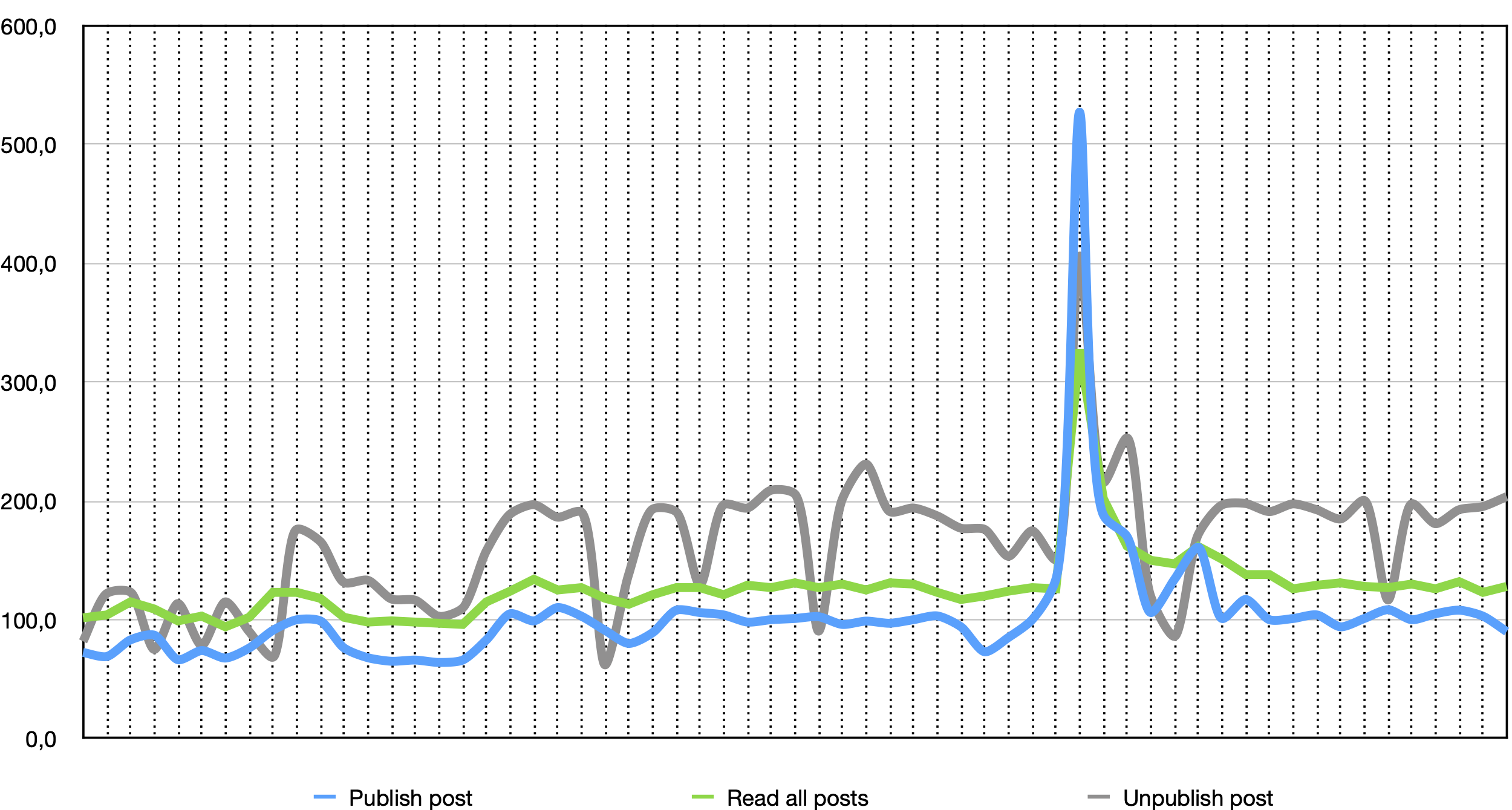
Времена отклика, мс (90-й персентиль)
Собственно, именно ради этого мы вообще этот шаг делали — надо понять, какая минимальная конфигурация позволит сделать совместимое по данным обновление без прерывания сервиса. А потом уже переходить непосредственно к обновлению БД.
Итак, посмотрим на причины ошибок:
Исправим эти проблемы:
А как с остальными пробами?Liveness- и readiness-пробы полезно иметь в сервисе, но в нашем случае я их не добавлял, поскольку целью было определить минимально достаточную конфигурацию для корректного обновления. Да и, честно говоря, полезность этих проб здорово преувеличивается. Liveness-проба говорит Kubenetes’у, что под надо убить. В качестве примера часто приводится deadlock, при котором приложение особо ничего не может сделать для решения проблемы, и проще запустить новый инстанс. Но я ни разу не видел, чтобы это реально детектилось на стороне приложения. С readiness-пробой то же самое. Это способ временно исключить под из маршрутизации, потому что мы считаем, что проблема пода временная и чуть позже сама разрешится. Но что это может быть за проблема, и почему мы считаем, что она связана именно с подом? Если у нас проблема с доступом к внешним ресурсам, то скорее всего, проблема на стороне внешних ресурсов (например, БД). Может, проблема и решится сама по себе, но надо понимать, что если проба фейлится, то K8S начинает перенаправлять трафик на другие поды. Другие поды, скорее всего, тоже не смогут достучаться до внешнего ресурса, только еще и получат кучу избыточного траффика, на который они не рассчитаны. Вам придется защищаться от этого добавляя rate limiter’ы и другие защитные механизмы, а в результате пользователь все равно не сможет воспользоваться сервисом. Наверное, в 9 приложениях из 10 на Spring Boot’е весь смысл этих проб — вызвать хоть что-нибудь, чтобы убедиться, что приложение еще не словило OOM и не израсходовало все коннекты HTTP-сервера. Это решается одной довольно примитивной liveness-пробой. Readiness-пробы раньше активно использовались для определения, когда на под можно пускать трафик при старте, но сейчас для этого есть startup-пробы. В общем, пробы, конечно, мощный инструмент, но не стоит его переоценивать, его очень не всегда удается адекватно применить.
Теперь при старте пода мы будем каждые 2 секунды вызывать readiness-ручку, пока она не ответит (не больше минуты). После того, как startup-проба прошла, на под будет маршрутизироваться трафик.
Повторим эксперимент с обновлением версии:
$ kubectl apply -f deployment.yaml
$ kubectl set image deployment/zero-dt-deployment zero-dt-app=zero-dt-app:1.0.2
Уже почти хорошо, но org.apache.http. NoHttpResponseException почему-то все еще есть (теперь их десятки, а не тысячи). W TF?
После того, как мы добавили graceful shutdown в наш сервис, он честно дорабатывает запросы, которые к нему уже пришли, и не пускает новые. Как именно не пускает — зависит от контейнера сервлетов, который использует Spring Boot Web. По умолчанию, это Tomcat, и он просто не дает установить соединение — отсюда и ошибки. А вот Undertow должен отвечать HTTP 503. Но откуда вообще новые запросы берутся? Почему K8S продолжает их маршрутизировать на под, который сам же только что остановил? Ну, если коротко, то потому что Kubernetes так работает: вот, например. Или вот статья на Хабре, где все очень подробно расписано (на мой взгляд, даже слишком подробно, про удаление подов там в самом конце).
А зачем они так сделали (ИМХО)?
Если подумать, то это логично со стороны авторов Kubernetes’а — вы все равно не сможете остановить моментально трафик на под в случае, когда он умер незапланировано (решение кейса, когда контейнер незапланировано умер — одна из основных причин существование Kubernetes’а в принципе). Поэтому клиенты вашего сервиса все равно не могут завязываться на то, что 100% запросов будет обработано. А если на это нельзя завязаться в случае аварийной остановки пода, то зачем усложнять себе жизнь, реализуя дополнительные гарантии для плановой остановки? Уже есть механизм, который исключит под из маршрутизации, хоть и с некоторой задержкой, пусть он и работает.
Мы хотели, чтобы при обновлении сервиса мы не получили ни одной ошибки. В реальной жизни это абсолютно избыточное требование, но здесь у нас тепличные условия эксперимента, можно и немного усложнить себе задачу. Поэтому воспользуемся рекомендованным методом разрешения этой ситуации, который выглядит надежным как швейцарский банк (добавим для пода preStop и в нем сделаем sleep на несколько секунд).
А как это вообще должно помочь?Kubernetes начнет удаление пода и пометит его как Terminating. Он выполнит preStop, а после его завершения пошлет сигнал SIGTERM. Но пока под выполняет sleep, информация о том, что этот под уже Terminating распространится по кластеру, и на него уже не будет маршрутизироваться трафик. Если кластер не успевает обработать эту информацию — увеличьте sleep, особенно это касается «настоящих» многонодных инсталляций. По сути, этот шаг делает необязательной установку server.shutdown = graceful на уровне приложения (основной кейс, когда он все еще будет полезен — наличие очень длительных запросов).
И еще раз повторяем обновление версии под нагрузкой:
$ kubectl apply -f deployment.yaml
$ kubectl set image deployment/zero-dt-deployment zero-dt-app=zero-dt-app:1.0.3
А вот теперь — нормально. org.apache.http. NoHttpResponseException полностью ушли, времена отклика немного подросли на момент переключения, но это ожидаемо.





