

Эта статья не будет затрагивать основы hibernate (как определить entity или написать criteria query). Тут я постараюсь рассказать о более интересных моментах, действительно полезных в работе. Информацию о которых я не встречал в одной месте.

Сразу оговорюсь. Все ниже изложенное справедливо для Hibernate 5.2. Также возможны ошибки в силу того, что я что-то неправильно понял. Если обнаружите — пишите.
- N+1 проблема
- 5.1. Постоянные сущности
- 5.2. Загрузка объектов
- 5.3. Отделение сущностей
- 5.4. Слияние сущностей
- 5.5. Запросы для сущностей
- 5.6. Удаление сущностей
- Table of contents
- Given problem
- Diving into some concepts in Hibernate framework
- Introduction to the Hibernate entity’s lifecycle
- Понимание контекста персистентности для каждого типа EntityManager
- Синхронизировать постоянный контекст с базой данных
- Wrapping up
- 1. Обзор
- 2. Различные способы удаления объектов
- 3. Удаление с помощью Entity Manager
- 4. Каскадное удаление
- 5. Удаление сирот
- 6. Удаление с использованием оператора JPQL
- 7. Удаление с использованием собственных запросов
- 8. Мягкое удаление
- 9. Заключение
- Дата и время
- Руководство по Hibernate EntityManager
- 1. Введение
- 2. Зависимости Maven
- 3. Конфигурация
- 3.1. Определение сущности
- 3.2. Файл persistence.xml Файл
- 4. Управление контейнером и приложением EntityManager
- 4.1. Управляемый контейнером EntityManager
- 4.2. Управляется приложением EntityManager
- 5. Операции с объектами в спящем режиме
- 5.1. Стойкие сущности
- 5.2. Загрузка объектов
- 5.3. Detaching Entities
- 5.4. Merging Entities
- 5.5. Querying for Entities
- 5.6. Removing Entities
- 6. Conclusion
- Set, Bag, List
- Проблемы отображения объектной модели в реляционную
- Проблема 2. Отношение композиции в ООП
- Batching
- Тестирование
- Entity Manager
- Deadlock
- Генераторы
- Сила References
- Литература
N+1 проблема
Это достаточно изъезженная тема, поэтому пробежимся по ней быстро.
N+1 проблема — это ситуация, когда вместо одного запроса на выбор N книг происходит по меньшей мере N+1 запрос.
Самый простой способ решения N+1 проблемы это сделать fetch связанных таблиц. В этом случае у нас может возникнуть несколько других проблем:
- Пагинация.
в случае отношений OneToMany hibernate не сможет указать offset и limit. Поэтому пагинация будет происходить in-memory. - Проблема декартова произведения
— это ситуация, когда на выбор N книг с M главами и K авторами база данных возвращает N*M*K строк.
Есть и другие способы решения N+1 проблемы.
- FetchMode
— позволяет изменить алгоритм загрузки дочерних сущностей. В нашем случае нас интересуют следующие:- FetchType. SUBSELECT
— загружает дочерние записи отдельным запросом. Минус в том, что вся сложность основного запроса повторяется в subselect-е. - BATCH (FetchType. SELECT + аннотация BatchSize)
— так же загружает записи отдельным запросом, но вместе subquery делает условие типа WHERE parent_id IN (?, ?, ?, …, N)
Стоит отметить, что при использовании fetch в Criteria API, FetchType игнорируется — всегда используется JOIN
- FetchType. SUBSELECT
- JPA EntityGraph и Hibernate FetchProfile
— позволяют вынести правила загрузки сущностей в отдельную абстракцию — на мой взгляд обе реализации неудобны.
Я сталкивался (да и не только я) с проблемой развертывания Hibernate и решил попробовать осветить данную тему. Hibernate — это популярный framework, цель которого связать ООП и реляционную базу данных. Работа с Hibernate сократит время разработки проекта в сравнении с обычным jdbc.
Для новичка программирования настройка framework часто вызывает затруднения. Помощь комьюнити с освещением базовых проблем поможет начинающим осваивать языки программирования быстрее. Статья предназначена только для начинающих в Java, которые впервые развертывают hibernate. Я развертывал hibernate на базе лицензионной IDEA.
Maven framework для автоматизации сборки проекта на основе POM, позволяющая подключать из интернета зависимости, не скачивая библиотеки в проект. P OM (project object model) -декларативное описание проекта. Копируем название библиотек в xml формате с сайта mvnrepository.com
.
Для начала создаёте структуру проекта maven:
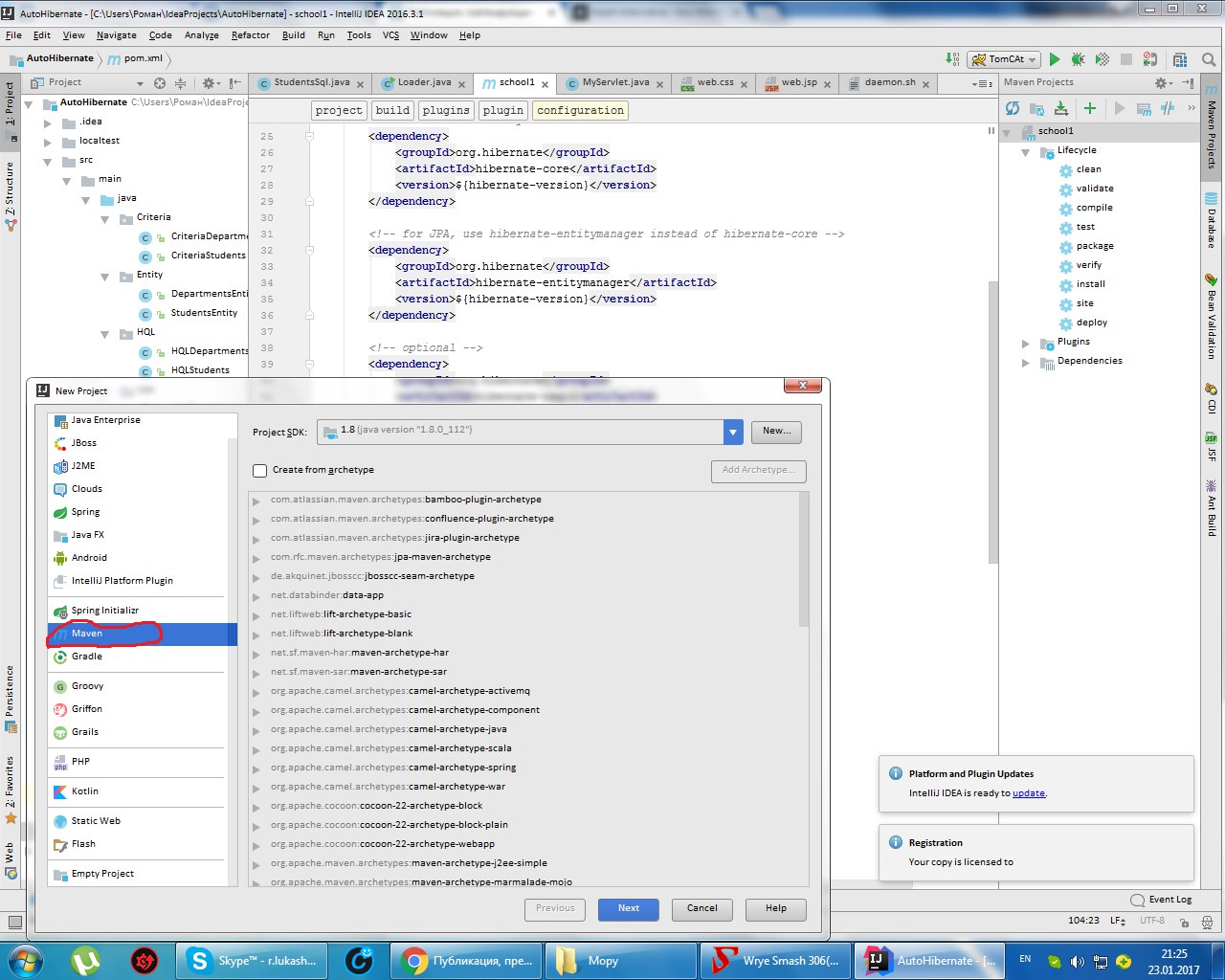
Потом в pom.xml вставляем. Нам понадобятся две зависимости: hibernate-core и mysql-connector, но если вы хотите больше функционала — вы должны подключить больше зависимостей.
Существуют стандартные рекомендации подключать зависимости по отдельности, но я так не делаю.
<properties>
<hibernate-version>5.0.1.Final</hibernate-version>
</properties>
<dependencies>
<!--driver for connection to MYSql database -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>
<!-- Hibernate -->
<!-- to start need only this -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>${hibernate-version}</version>
</dependency>
<!-- for JPA, use hibernate-entitymanager instead of hibernate-core -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${hibernate-version}</version>
</dependency>
</dependencies>
И щелкаем на Import Changes Enable Auto-Import, автоматически импортируя изменения.
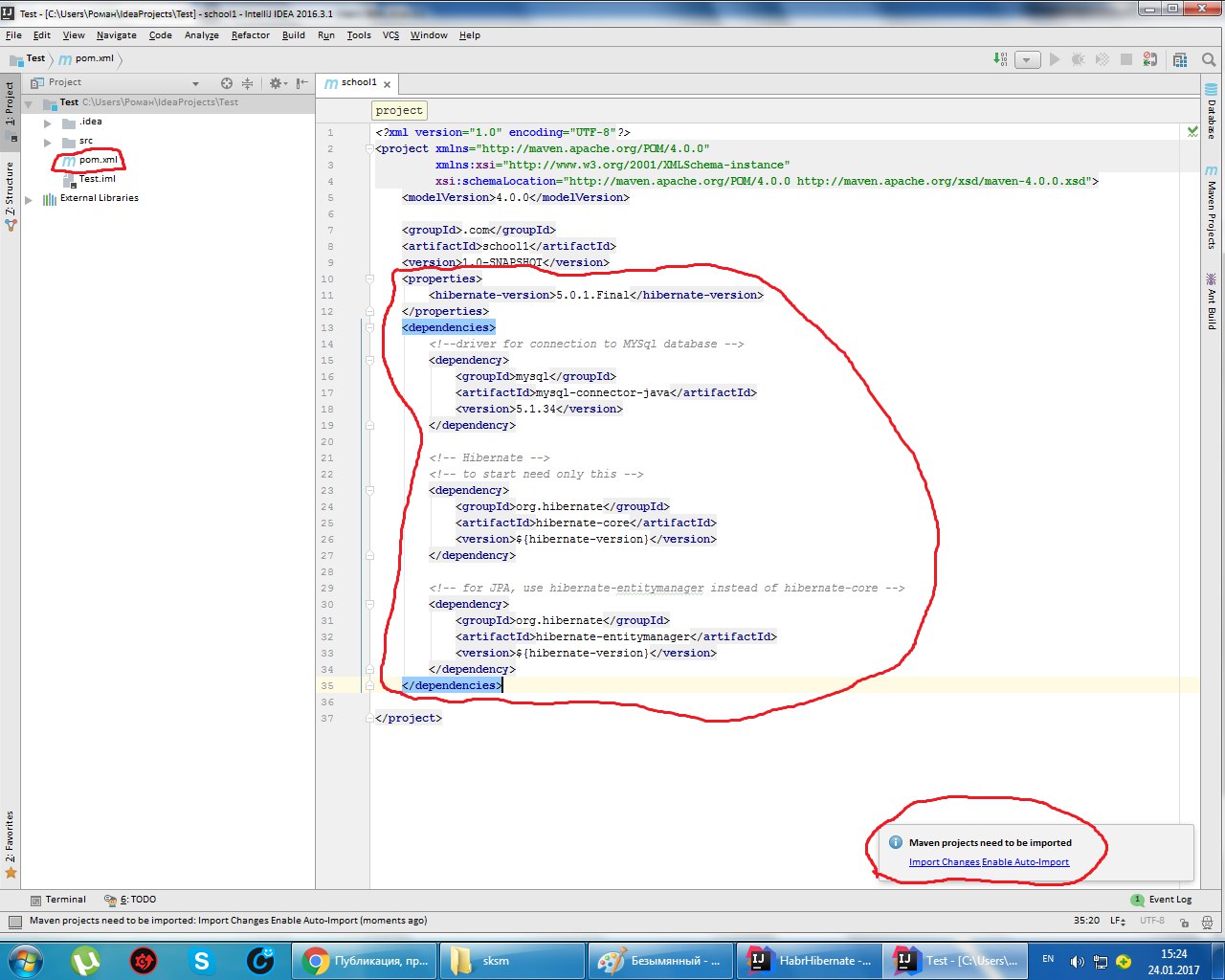
Подключаемся к базе данных, которая развернута на локальном компьютере, выбираем поставщика баз данных MySQL.
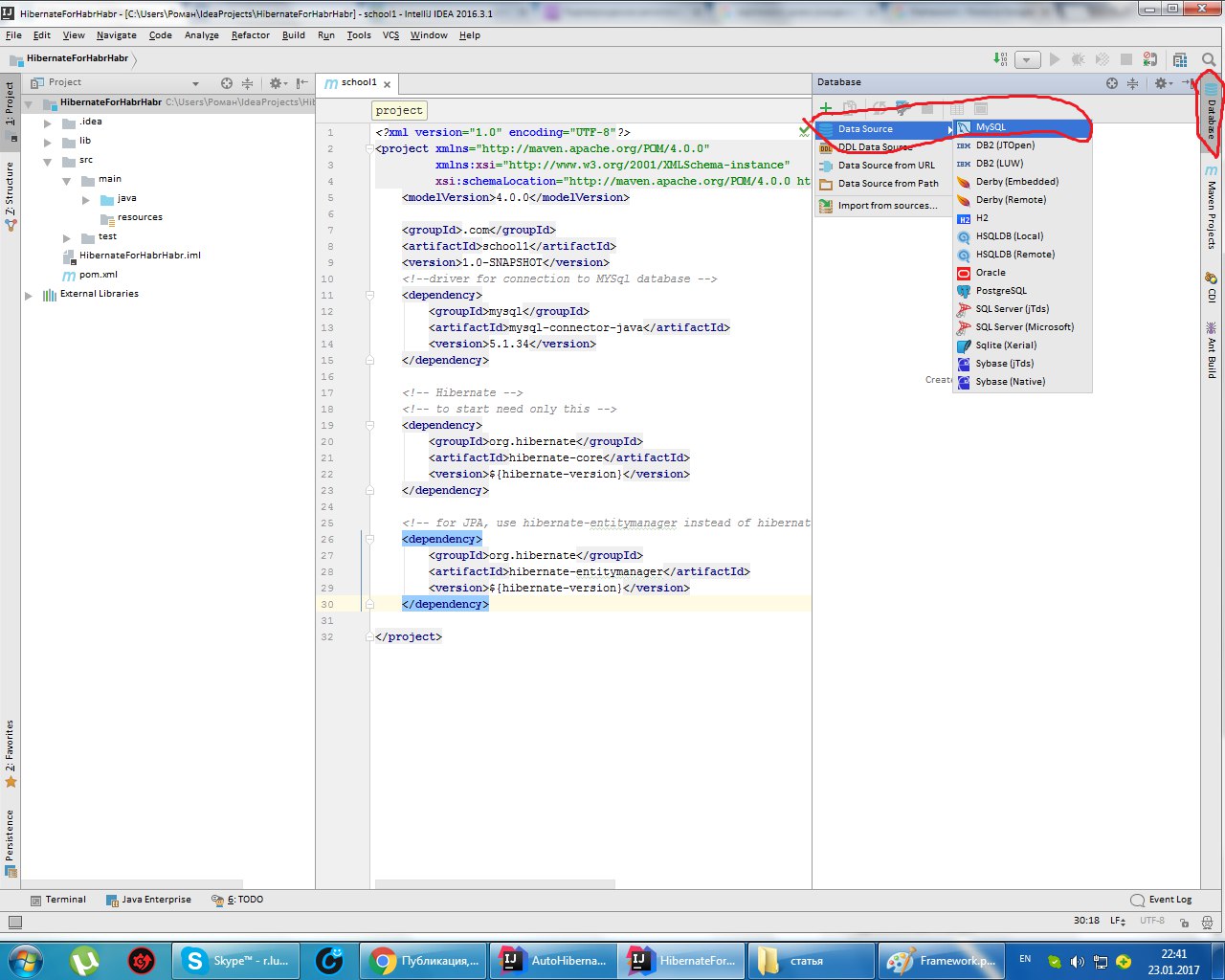
Вводим имя базы данных, имя пользователя и пароль. Протестируйте соединение.
Выбираем проект и через framework support просим у хибернейта создать за нас Entity файлы и классы с Getter и Setter.
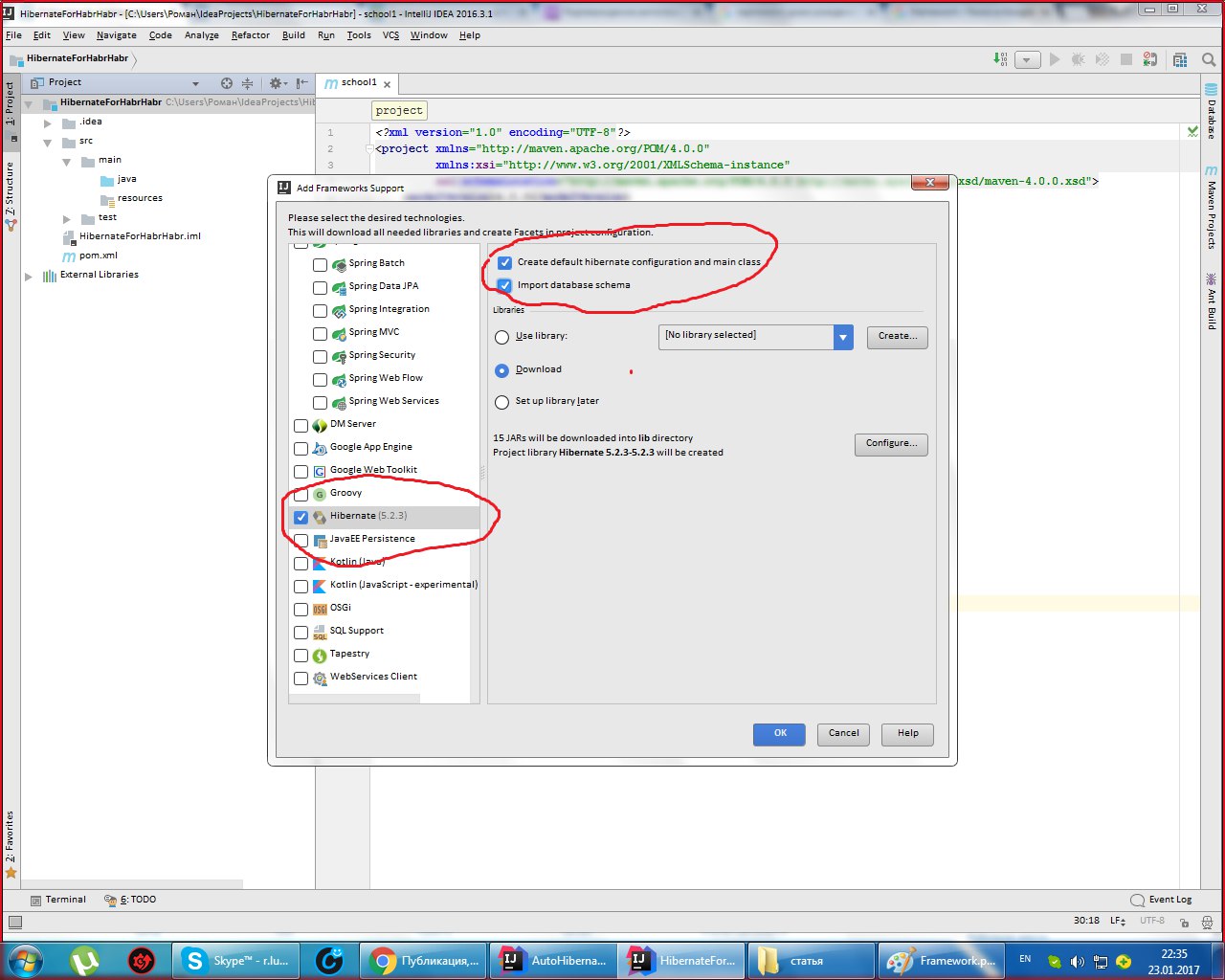
Выбираем Generate Persistence Mapping через кладку Persistence, выбираем jenerate Persistance Mapping, а в появившемся окне прописываем схему базы данных, выбираем prefix и
sufix к автоматически сгенерированным названиям. Будут сгенерированы названия xml файлов и классов с аннотациями:
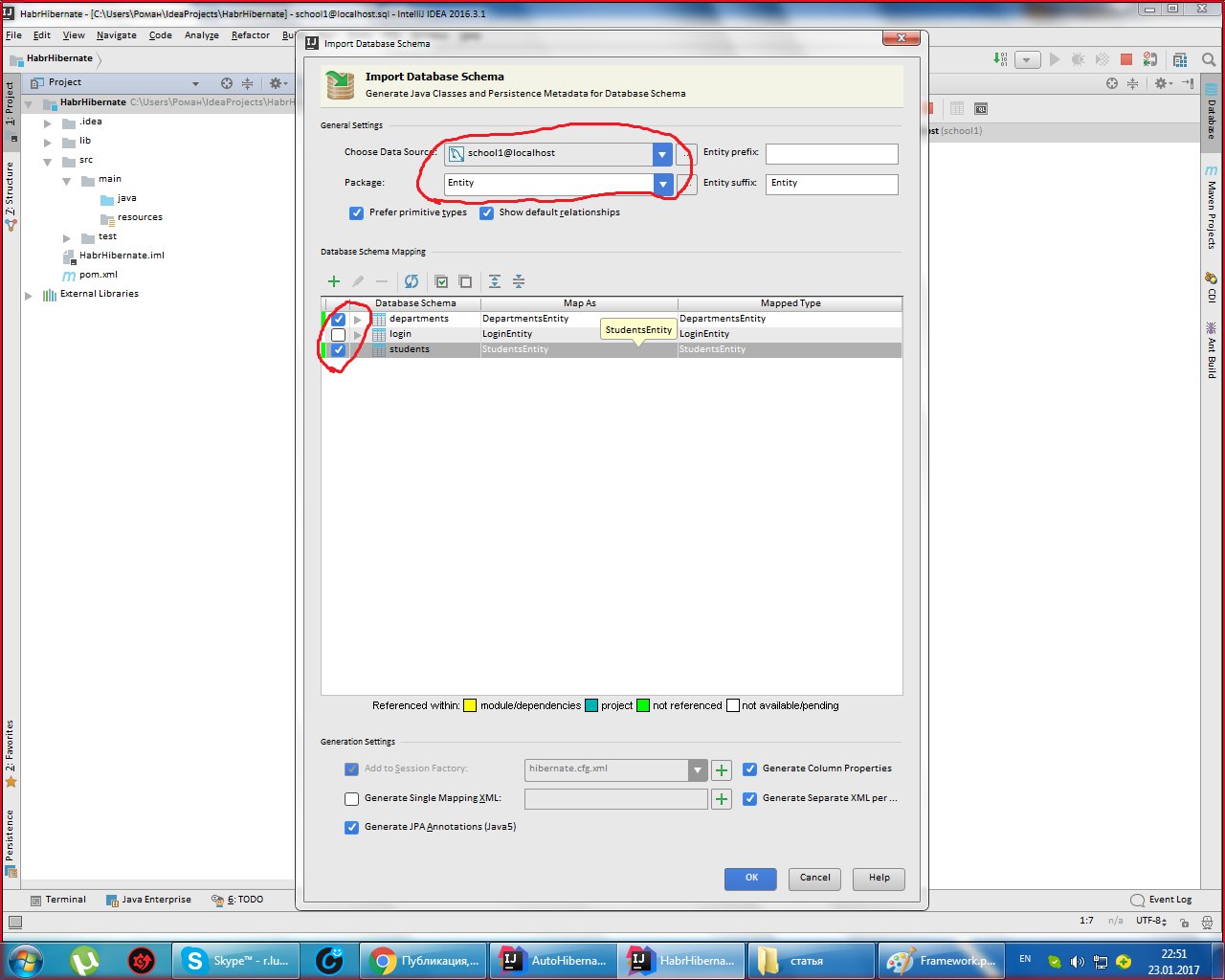
Раскидайте файлы в таком порядке:
.xml-файлы должны находится в папке с ресурсами, а сущности в папке java.
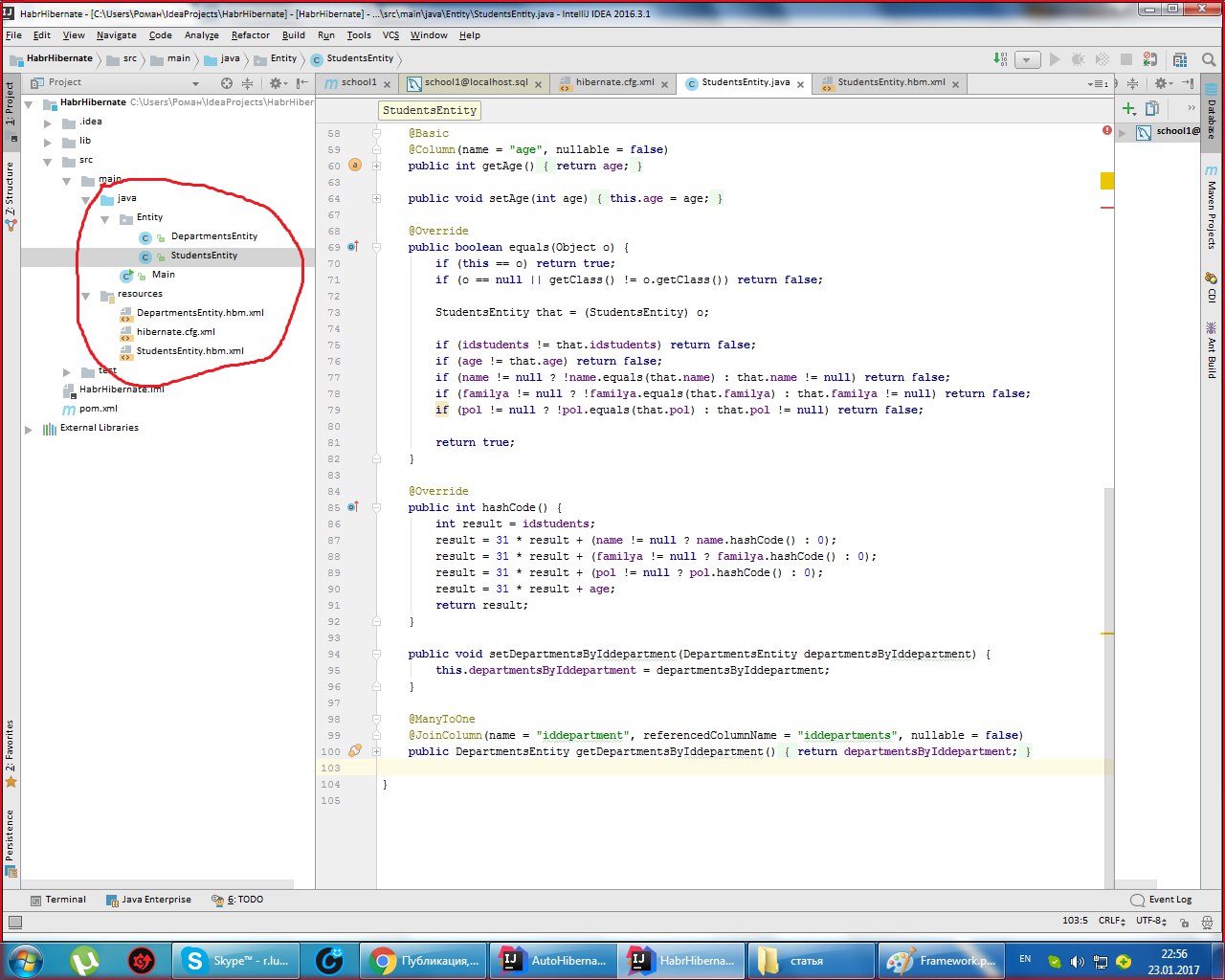
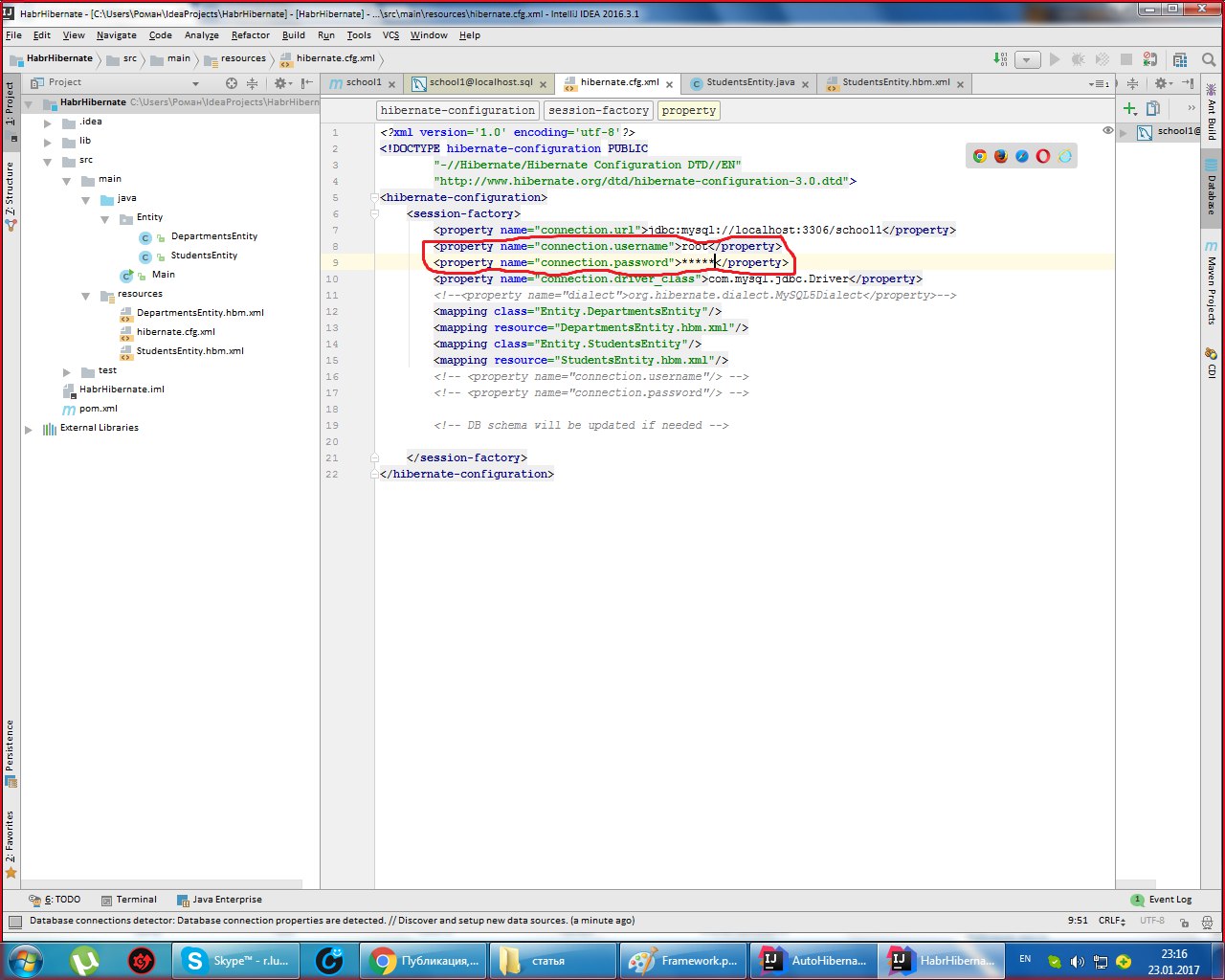
Вот и все! Дальше через класс main запускаем проект.
Это моя первая статья. Рассчитываю на здравую критику.
API EntityManager
предоставляет набор методов. Мы можем взаимодействовать с базой данных, используя эти методы.
5.1. Постоянные сущности
Чтобы иметь объект, связанный с EntityManager, мы можем использовать метод persist()
:
public void saveMovie() {
EntityManager em = getEntityManager();
em.getTransaction().begin();
Movie movie = new Movie();
movie.setId(1L);
movie.setMovieName("The Godfather");
movie.setReleaseYear(1972);
movie.setLanguage("English");
em.persist(movie);
em.getTransaction().commit();
}
После сохранения объекта в базе данных он находится в состоянии persistent
.
5.2. Загрузка объектов
Для получения объекта из базы данных мы можем использовать метод find()
.
Здесь метод выполняет поиск по первичному ключу. Фактически, метод ожидает тип класса сущности и первичный ключ:
public Movie getMovie(Long movieId) {
EntityManager em = getEntityManager();
Movie movie = em.find(Movie.class, new Long(movieId));
em.detach(movie);
return movie;
}
However, if we just need the reference to the entity, we can use the getReference()
вместо этого. По сути, он возвращает прокси для сущности:
Movie movieRef = em.getReference(Movie.class, new Long(movieId));
5.3. Отделение сущностей
В случае, если нам нужно отсоединить объект от контекста постоянства, we can use the detach()
method
. Мы передаем объект, который будет отсоединен, в качестве параметра методу:
Как только объект отсоединен от контекста постоянства, он будет в отключенном состоянии.
5.4. Слияние сущностей
На практике многие приложения требуют модификации сущности для нескольких транзакций. Например, мы можем захотеть получить сущность в одной транзакции для рендеринга в пользовательский интерфейс. Затем другая транзакция внесет изменения, сделанные в пользовательском интерфейсе.
В таких ситуациях мы можем использовать метод merge()
. The merge method helps to bring in the modifications made to the detached entity, in the managed entity, if any:
public void mergeMovie() {
EntityManager em = getEntityManager();
Movie movie = getMovie(1L);
em.detach(movie);
movie.setLanguage("Italian");
em.getTransaction().begin();
em.merge(movie);
em.getTransaction().commit();
}
5.5. Запросы для сущностей
Кроме того, мы можем использовать JPQL для запроса сущностей. Мы вызовем getResultList()
для их выполнения.
Конечно, мы можем использовать getSingleResult(),
, если запрос возвращает только один объект:
public List queryForMovies() {
EntityManager em = getEntityManager();
List movies = em.createQuery("SELECT movie from Movie movie where movie.language = ?1")
.setParameter(1, "English")
.getResultList();
return movies;
}
5.6. Удаление сущностей
Дополнительно we can remove an entity from the database using the remove()
method
. Важно отметить, что объект не отсоединяется, а удаляется.
Здесь состояние объекта меняется с постоянного на новое:
public void removeMovie() {
EntityManager em = HibernateOperations.getEntityManager();
em.getTransaction().begin();
Movie movie = em.find(Movie.class, new Long(1L));
em.remove(movie);
em.getTransaction().commit();
}
Table of contents
Given problem
Suppose that we have a segment of code:
How do we understand about the Student entity in Hibernate internally?
To be aware of the entity in Hibernate framework, we need to know more about the entity’s state.
Diving into some concepts in Hibernate framework
Before jumping directly into the lifecycle of the entity’s state in Hibernate, we need to be aware of some concepts’s definition.
Introduction to the Hibernate entity’s lifecycle
At this time, we will continue to discuss about the lifecycle of an entity or about the entity’s states.
Below is an image that describe the relationship between an entity’s state.
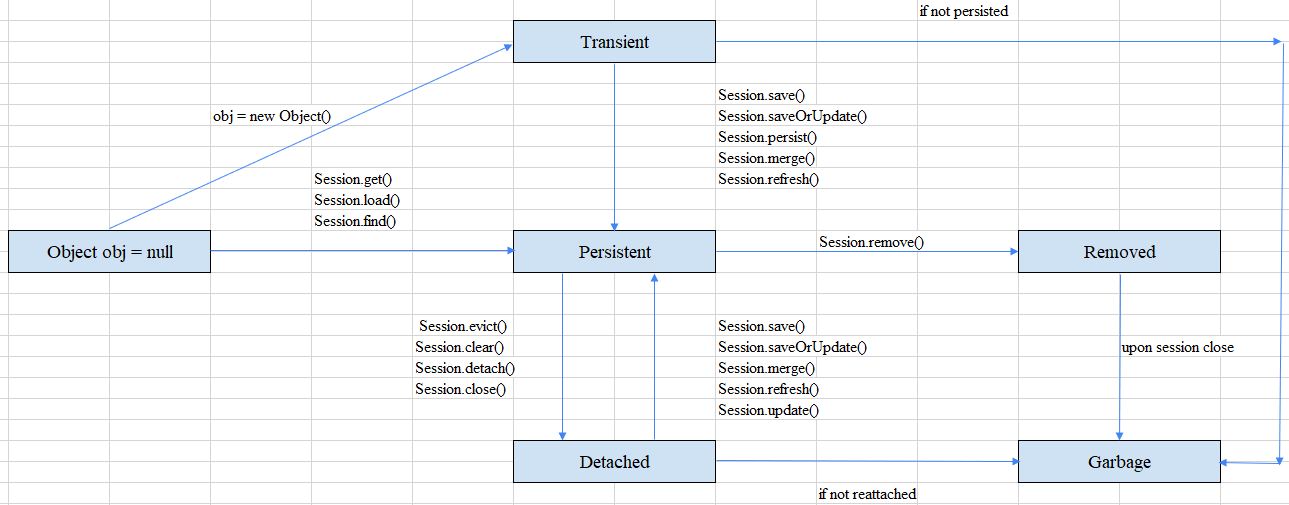
An entity object is instantiated by using new operator, that will be called as a transient object.
The Persistence Context doesn’t managed it. And of course, this transient object doesn’t associated with
From the transient state to persistent state, there are some methods that supports:
// Hibernate 5.4If the persist() method is called on the detached object, IllegalArgumentException will be thrown.
A persistent object is an object that associates with a database record. From that, the Persistence Context will manage it, and cache that object state, easily be aware of its modification.
To retrieve the persistent object from a database, some methods will supports:
Some methods to convert the persistent object to detached object.
// from EntityManager interface // from EntityManager interfaceПосле закрытия транзакции контекст персистентности не существует. Тогда приложение по-прежнему будет иметь ссылку на объект в этом постоянном контексте. Таким образом, этот объект считается отдельным объектом.
Ниже приведены некоторые способы преобразования постоянного объекта в отдельный объект.
- Когда транзакция (в постоянном контексте области транзакции) фиксируется, объекты, управляемые постоянным контекстом, становятся отсоединенными.
- Если контекст персистентности, управляемый приложением, закрыт, все управляемые объекты становятся отсоединенными.
- Использование методов detach(), evict(),clear() и close().
- Будет вызвано действие отката.
- В контексте расширенного персистентности, когда bean-компонент с состоянием удаляется, все управляемые объекты становятся отсоединенными.
Некоторые методы преобразования отсоединенного объекта в постоянный объект:
Прежде чем отделять сущность, мы должны не забыть сбросить
все изменения в контексте сохранения в базе данных.
Когда метод delete() или Remove() вызывается для постоянного объекта, этот объект будет преобразован в отсоединенный объект.
Когда объект удаляется, контекст сохранения удаляет объект из базы данных. Это означает, что нам не следует использовать какие-либо ссылки на удаленный объект в приложении, потому что если какие-то изменения произойдут в этих ссылках, это не отразится на базе данных.
Если метод удаления() вызывается для отсоединенного объекта, будет выброшено исключение IllegalArgumentException. В противном случае метод удаления() вызывается для постоянного объекта, который находится в двунаправленной связи (с использованием cascade = REMOVE или cascade = ALL) с другим постоянным объектом, после чего для этого постоянного объекта будет вызвана операция удаления. Если метод Remove() вызывается для удаленного объекта, ничего не происходит.
// из интерфейса EntityManager
Понимание контекста персистентности для каждого типа EntityManager
PersistenceContextType
перечисление имеет два значения:- РАСШИРЕННЫЙ
— расширенный контекст персистентности СДЕЛКА
— контекст персистентности в области транзакции.По умолчанию значение PersistenceContextType. ТРАНЗАКЦИЯ
используется.
Ниже приведена некоторая информация о типе контекста персистентности в EntityManager, управляемом контейнером.
Контекст персистентности на уровне транзакции
Мы можем прочитать о контексте персистентности в области транзакций в разделе Погружение в некоторые концепции Hibernate framework
.Расширенный контекст персистентности
Мы можем прочитать о расширенном контексте персистентности в разделе Погружение в некоторые концепции Hibernate framework
.Контекст сохранения создается после вызова EntityManagerFactory.createEntityManager()
метод. Когда контекст персистентности освобождается путем вызова EntityManager.close()
метода, объекты в этом контексте персистентности будут находиться в отключенном состоянии.
- РАСШИРЕННЫЙ
При использовании EntitManager, управляемого приложением, мы вызываем createEntityManager()
метод для создания нового EntityManager
экземпляр, то он будет использовать только Расширенный контекст персистентности
соответствующий этому EntityManager.После вызова EntityManagerFactory.createEntityManager() создается контекст персистентности
метод. Когда контекст персистентности освобождается путем вызова EntityManager.close()
метода, объекты в этом контексте персистентности будут находиться в отключенном состоянии.
Синхронизировать постоянный контекст с базой данных
Ниже приведены некоторые случаи, когда контекст сохранения синхронизируется с базой данных.
после фиксации транзакции.
после вызова методаlush() в этом сеансе.
Методlush() обновляет базу данных измененными копиями объектов.
Refresh() обновляет объектную модель последней копией записей, считывая их из базы данных.
Теперь продолжим работу с режимом смыва. Этот режим очистки может повлиять на производительность при запросе.
Consider about the FlushMode enum:
// The Session is flushed before every query // The Session is sometimes flushed before every query execution in order to ensure that queries never return stale state // The Session is flushed when EntityManager.commit() is called // The Session is only ever flushed when Session.flush() is explictly called by the application
Wrapping up
- With the container-managed EntityManager, the persistence context is shared across the multiple Spring Beans or JavaEE’s application components. Otherwise, it’s not right for the application-managed EntityManager.
1. Обзор
Как полнофункциональная платформа ORM, Hibernate отвечает за управление жизненным циклом постоянных объектов (объектов), включая операции CRUD, такие как
read
,
save
,
update
и
delete
.
В этой статье мы рассмотрим различные
способы удаления объектов из базы данных с помощью Hibernate
и объясним типичные проблемы и возможные подводные камни.
Мы используем JPA и делаем шаг назад и используем нативный API Hibernate для тех функций, которые не стандартизированы в JPA.
2. Различные способы удаления объектов
Объекты могут быть удалены в следующих случаях:
Когда удаление каскадно из других экземпляров объекта
Выполняя нативные запросы
Применяя метод мягкого удаления (фильтрация мягко удаленных объектов
В оставшейся части статьи мы рассмотрим эти моменты подробно.
3. Удаление с помощью Entity Manager
Удаление с помощью
EntityManager
— самый простой способ удаления экземпляра объекта:
Foo foo = new Foo("foo");
entityManager.persist(foo);
flushAndClear();
foo = entityManager.find(Foo.class, foo.getId());
assertThat(foo, notNullValue());
entityManager.remove(foo);
flushAndClear();
assertThat(entityManager.find(Foo.class, foo.getId()), nullValue());
В примерах в этой статье мы используем вспомогательный метод для очистки и очистки контекста персистентности, когда это необходимо:
void flushAndClear() {
entityManager.flush();
entityManager.clear();
}
После вызова метода
EntityManager.remove
предоставленный экземпляр переходит в состояние
removed
, и соответствующее удаление из базы данных происходит при следующей очистке.
@Entity
public class Foo {
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
private Bar bar;
//other mappings, getters and setters
}
Когда мы удаляем экземпляр
Bar
, на который ссылается экземпляр
Foo
, который также загружается в контексте постоянства, экземпляр
Bar
не будет удален из базы данных:
Bar bar = new Bar("bar");
Foo foo = new Foo("foo");
foo.setBar(bar);
entityManager.persist(foo);
flushAndClear();
foo = entityManager.find(Foo.class, foo.getId());
bar = entityManager.find(Bar.class, bar.getId());
entityManager.remove(bar);
flushAndClear();
bar = entityManager.find(Bar.class, bar.getId());
assertThat(bar, notNullValue());
foo = entityManager.find(Foo.class, foo.getId());
foo.setBar(null);
entityManager.remove(bar);
flushAndClear();
assertThat(entityManager.find(Bar.class, bar.getId()), nullValue());
Если на удаленный
Bar
ссылается
Foo
, операция
PERSIST
каскадно переходит из
Foo
в
Bar
, поскольку ассоциация помечена как
cascade = CascadeType. ALL
и удаление не запланировано. Чтобы убедиться, что это происходит, мы можем включить уровень журнала трассировки для пакета
org.hibernate
и выполнить поиск записей, таких как
un-scheduling entity deletion
.
4. Каскадное удаление
Удаление может быть связано с дочерними объектами при удалении родителей:
Bar bar = new Bar("bar");
Foo foo = new Foo("foo");
foo.setBar(bar);
entityManager.persist(foo);
flushAndClear();
foo = entityManager.find(Foo.class, foo.getId());
entityManager.remove(foo);
flushAndClear();
assertThat(entityManager.find(Foo.class, foo.getId()), nullValue());
assertThat(entityManager.find(Bar.class, bar.getId()), nullValue());
Здесь
bar
удаляется, потому что удаление связано с
foo
, так как объявляется, что ассоциация каскадирует все операции жизненного цикла от
Foo
до
Bar
.
5. Удаление сирот
Директива
orphanRemoval
объявляет, что связанные экземпляры сущностей должны быть удалены, когда они отсоединены от родителя, или эквивалентно, когда родитель удален.
Мы показываем это, определяя такую связь от
Bar
до
Baz:
@Entity
public class Bar {
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
private List<Baz> bazList = new ArrayList<>();
//other mappings, getters and setters
}
Затем экземпляр
Baz
удаляется автоматически, когда он удаляется из списка родительского экземпляра
Bar
:
Bar bar = new Bar("bar");
Baz baz = new Baz("baz");
bar.getBazList().add(baz);
entityManager.persist(bar);
flushAndClear();
bar = entityManager.find(Bar.class, bar.getId());
baz = bar.getBazList().get(0);
bar.getBazList().remove(baz);
flushAndClear();
assertThat(entityManager.find(Baz.class, baz.getId()), nullValue());
Семантика операции
orphanRemoval
полностью аналогична операции
REMOVE
, применяемой непосредственно к затронутым дочерним экземплярам ** , что означает, что операция
REMOVE
далее каскадируется для вложенных дочерних элементов. Как следствие, вы должны убедиться, что другие экземпляры не ссылаются на удаленные (в противном случае они сохраняются повторно).
6. Удаление с использованием оператора JPQL
Hibernate поддерживает операции удаления в стиле DML:
Foo foo = new Foo("foo");
entityManager.persist(foo);
flushAndClear();
entityManager.createQuery("delete from Foo where id = :id")
.setParameter("id", foo.getId())
.executeUpdate();
assertThat(entityManager.find(Foo.class, foo.getId()), nullValue());
Важно отметить, что операторы JPQL в стиле DML не влияют ни на состояние, ни на жизненный цикл экземпляров сущностей, которые уже загружены в контекст постоянства ** , поэтому рекомендуется выполнять их до загрузки затронутых сущностей.
7. Удаление с использованием собственных запросов
Иногда нам нужно обратиться к собственным запросам, чтобы достичь чего-то, что не поддерживается Hibernate или специфично для поставщика базы данных.
Мы также можем удалить данные в базе данных с помощью собственных запросов:
Foo foo = new Foo("foo");
entityManager.persist(foo);
flushAndClear();
entityManager.createNativeQuery("delete from FOO where ID = :id")
.setParameter("id", foo.getId())
.executeUpdate();
assertThat(entityManager.find(Foo.class, foo.getId()), nullValue());
Та же рекомендация применяется к собственным запросам, что и к операторам JPA-стиля DML, т. Е.
Собственные запросы не влияют ни на состояние, ни на жизненный цикл экземпляров сущностей, которые загружаются в контекст постоянства до выполнения запросов
.
8. Мягкое удаление
Часто нежелательно удалять данные из базы данных из-за целей аудита и ведения истории. В таких ситуациях мы можем применить метод, называемый мягким удалением. По сути, мы просто помечаем строку как удаленную и отфильтровываем ее при извлечении данных.
@Entity
@Where(clause = "DELETED = 0")
public class Foo {
//other mappings
@Column(name = "DELETED")
private Integer deleted = 0;
//getters and setters
public void setDeleted() {
this.deleted = 1;
}
}
Следующий тест подтверждает, что все работает как положено:
Foo foo = new Foo("foo");
entityManager.persist(foo);
flushAndClear();
foo = entityManager.find(Foo.class, foo.getId());
foo.setDeleted();
flushAndClear();
assertThat(entityManager.find(Foo.class, foo.getId()), nullValue());
9. Заключение
В этой статье мы рассмотрели различные способы удаления данных с помощью Hibernate. Мы объяснили основные концепции и некоторые лучшие практики. Мы также продемонстрировали, как программные удаления могут быть легко реализованы с помощью Hibernate.
Реализация этого Руководства по удалению объектов с помощью Hibernate доступна на
over на Github
. Это проект, основанный на Maven, поэтому его легко импортировать и запускать как есть.
Дата и время
Не смотря на то что в java 8 появилось прекрасное API для работы с датой и временем, JDBC API по прежнему позволяет работать только со старым API дат. Поэтому разберем некоторые интересные моменты.
Во-первых, нужно четко понимать отличия LocalDateTime от Instant и от ZonedDateTime. ( Не буду растягивать, а приведу отличные статьи на эту тему: первая
и вторая
)
LocalDateTime и LocalDate представляют обычный кортеж чисел. Они не привязаны к конкретному времени. Т.е. время посадки самолета хранить в LocalDateTime нельзя. А дату рождения через LocalDate вполне нормально. Instant же представляет точку во времени, относительно которой мы можем получить локальное время в любой точке на планете.
Более интересный и важный момент — как даты сохраняется в базу данных. Если у нас проставлен тип TIMESTAMP WITH TIMEZONE то проблем быть не должно, если же стоит TIMESTAMP (WITHOUT TIMEZONE) то есть вероятность, что дата запишется/прочитается неверная. (за исключением LocalDate и LocalDateTime)
Давайте разберемся почему:
Когда мы сохраняем дату, используется метод со следующей сигнатурой:
setTimestamp(int i, Timestamp t, java.util.Calendar cal)
Как видим тут используется старое API. Дополнительный аргумент Calendar нужен для того, чтобы преобразовать timestamp в строковое представление. т.е он хранит в себе timezone-у. Если Calendar не передается, то используется Calendar по-умолчанию с таймзоной JVM.
Решить эту проблему можно 3 способами:
- Устанавливать нужную timezone JVM
- Использовать параметр hibernate — hibernate.jdbc.time_zone (добавлена в 5.2) — починит только ZonedDateTime и OffsetDateTime
- Использовать тип TIMESTAMP WITH TIMEZONE
Интересный вопрос, почему LocalDate и LocalDateTime не подпадают под такую проблему?
Для ответа на этот вопрос нужно понимать структуру класса java.util. Date (java.sql. Date и java.sql. Timestamp его наследники и их отличия в данном случае нас не волнуют). Date хранит дату в миллисекундах c 1970 года грубо говоря в UTC, но метод toString преобразует дату согласно системной timeZone.
Соответственно, когда мы получаем из базы данных дату без таймзоны, она отображатеся в объект Timestamp, так чтобы метод toString отобразил ее желаемое значение. При этом количество миллисекунд с 1970-го года может отличаться (в зависимости от временной зоны). Именно поэтому только локальное время отображается всегда корректно.
Также привожу пример кода, ответственный за преобразование Timesamp в LocalDateTime и Instant:
// LocalDateTime
LocalDateTime.ofInstant( ts.toInstant(), ZoneId.systemDefault() );
// Instant
ts.toInstant();
Руководство по Hibernate EntityManager
1. Введение
Менеджер сущностей
является частью Java Persistence API. Главным образом, он реализует программные интерфейсы и правила жизненного цикла, определенные спецификацией JPA 2.0.
Более того, мы можем получить доступ к контексту постоянства, используя API в EntityManager
.
В этом уроке мы рассмотрим конфигурацию, типы и различные API EntityManager .
.
2. Зависимости Maven
Во-первых, нам нужно включить зависимости Hibernate:
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.4.0.Final</version>
</dependency>
Нам также придется включить зависимости драйвера, в зависимости от базы данных, которую мы используем:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
3. Конфигурация
Теперь давайте продемонстрируем EntityManager
, используя Фильм
сущность, которая соответствует таблице MOVIE в базе данных.
В этой статье мы будем использовать EntityManager
API для работы с фильмом
объекты в базе данных.
3.1. Определение сущности
@Entity
@Table(name = "MOVIE")
public class Movie {
@Id
private Long id;
private String movieName;
private Integer releaseYear;
private String language;
// standard constructor, getters, setters
}
3.2. Файл persistence.xml
Файл
Когда EntityManagerFactory
создается, реализация персистентности ищет META-INF/persistence.xml
файл в пути к классам
.
Этот файл содержит конфигурацию для EntityManager
:
<persistence-unit name="com.baeldung.movie_catalog">
<description>Hibernate EntityManager Demo</description>
<class>com.baeldung.hibernate.pojo.Movie</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5Dialect"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://127.0.0.1:3306/moviecatalog"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value="root"/>
</properties>
</persistence-unit>
Чтобы объяснить, мы определяем единицу персистентности, которая определяет базовое хранилище данных, управляемое EntityManager
.
Кроме того, мы определяем диалект и другие свойства JDBC базового хранилища данных. Hibernate не зависит от базы данных. На основе этих свойств Hibernate подключается к базовой базе данных.
4. Управление контейнером и приложением EntityManager
По сути, существует два типа EntityManager
– Управление контейнером и управление приложением.
Давайте подробнее рассмотрим каждый тип.
4.1. Управляемый контейнером EntityManager
Здесь контейнер внедряет EntityManager
в компонентах нашего предприятия.
Другими словами, контейнер создает EntityManager
из EntityManagerFactory
для нас:
@PersistenceContext
EntityManager entityManager;
Это также означает контейнер отвечает за начало, подтверждение или откат транзакции.
4.2. Управляется приложением EntityManager
И наоборот, жизненный цикл EntityManager
управляется приложением здесь.
Фактически, мы вручную создадим EntityManager.
Кроме того, мы также будем управлять жизненным циклом EntityManager .
мы создали.
Во-первых, давайте создадим EntityManagerFactory:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("com.baeldung.movie_catalog");
Чтобы создать EntityManager
, мы должны явно вызвать createEntityManager()
в EntityManagerFactory
:
public static EntityManager getEntityManager() {
return emf.createEntityManager();
}
5. Операции с объектами в спящем режиме
EntityManager
API предоставляет набор методов. Мы можем взаимодействовать с базой данных, используя эти методы.
5.1. Стойкие сущности
Чтобы иметь объект, связанный с EntityManager, мы можем использовать persist()
метод :
public void saveMovie() {
EntityManager em = getEntityManager();
em.getTransaction().begin();
Movie movie = new Movie();
movie.setId(1L);
movie.setMovieName("The Godfather");
movie.setReleaseYear(1972);
movie.setLanguage("English");
em.persist(movie);
em.getTransaction().commit();
}
Как только объект сохраняется в базе данных, он становится постоянным
состояние.
5.2. Загрузка объектов
Для получения объекта из базы данных мы можем использовать find()
метод.
Здесь метод выполняет поиск по первичному ключу. Фактически, метод ожидает тип класса сущности и первичный ключ:
public Movie getMovie(Long movieId) {
EntityManager em = getEntityManager();
Movie movie = em.find(Movie.class, new Long(movieId));
em.detach(movie);
return movie;
}
Однако, если нам просто нужна ссылка на объект, мы можем использовать getReference()
вместо этого метод. In effect, it returns a proxy to the entity:
Movie movieRef = em.getReference(Movie.class, new Long(movieId));
5.3. Detaching Entities
In the event that we need to detach an entity from the persistence context, we can use the detach()
method
. We pass the object to be detached as the parameter to the method:
Once the entity is detached from the persistence context, it will be in the detached state.
5.4. Merging Entities
In practice, many applications require entity modification across multiple transactions. For example, we may want to retrieve an entity in one transaction for rendering to the UI. Then, another transaction will bring in the changes made in the UI.
We can make use of the merge()
method, for such situations. The merge method helps to bring in the modifications made to the detached entity, in the managed entity, if any:
public void mergeMovie() {
EntityManager em = getEntityManager();
Movie movie = getMovie(1L);
em.detach(movie);
movie.setLanguage("Italian");
em.getTransaction().begin();
em.merge(movie);
em.getTransaction().commit();
}
5.5. Querying for Entities
Furthermore, we can make use of JPQL to query for entities. We’ll invoke getResultList()
to execute them.
Of course, we can use the getSingleResult(),
if the query returns just a single object:
public List<?> queryForMovies() {
EntityManager em = getEntityManager();
List<?> movies = em.createQuery("SELECT movie from Movie movie where movie.language = ?1")
.setParameter(1, "English")
.getResultList();
return movies;
}
5.6. Removing Entities
Additionally, we can remove an entity from the database using the remove()
method
. It’s important to note that, the object is not detached, but removed.
Here, the state of the entity changes from persistent to new:
public void removeMovie() {
EntityManager em = HibernateOperations.getEntityManager();
em.getTransaction().begin();
Movie movie = em.find(Movie.class, new Long(1L));
em.remove(movie);
em.getTransaction().commit();
}
6. Conclusion
In this article, we have explored the EntityManager
in Hibernate
. We’ve looked at the types and configuration, and we learned about the various methods available in the API for working with the persistence context.
As always, the code used in the article is available over at Github
.
Set, Bag, List
В hibernate есть 3 основных способа представить коллекцию связи OneToMany.
- Set — неупорядоченное множество сущностей без повторений;
- Bag — неупорядоченное множество сущностей;
- List — упорядоченное множество сущностей.
Для Bag в java core нет класса, который бы описывал такую структуру. Поэтому все List и Collection — являются bag-ом если не указана колонка, по которой наша коллекция будет сортироваться(аннотация OrderColumn. Не путать с SortBy). Использовать аннотацию OrderColumn крайне не рекомендую в силу плохой (на мой взгляд) реализации фичи — не оптимальные sql запросы, возможное наличие NULL-ов в листе.
Возникает вопрос, а что все-таки лучше использовать bag или set? Начнем с того, что при использовании bag-а возможны следующие проблемы:
- Если ваша версия hibernate ниже 5.0.8, то существует довольно серьезный баг — HHH-5855
— при инсерте дочерней сущности возможно ее дублирование (в случае cascadType=MERGE and PERSIST); - Если вы используете bag для отношения ManyToMany, то hibernate генерирует крайне не оптимальные запросы при удалении сущности из коллекции — он сначала удаляет все строки из связывающей таблицы, а потом выполняет insert;
- Hibernate не может выполнить одновременный fetch нескольких bag-ов для одной сущности.
// используем bag
spaceCraft.getCrew().add( luke ); // весь экипаж не загружается из бд
// используем set
spaceCraft.getCrew().put( luke ); // весь экипаж загружается из бд
// хотя вышеописанный вариант связывания мне не очень нравится. На мой взгляд связь ManyToOne удобнее указывать так:
luke.setCurrentSpaceCraft( spaceCraft );
Проблемы отображения объектной модели в реляционную
Но начнем все же с основ ORM. O RM — объектно-реляционное отображение — соответственно у нас есть реляционная и объектная модели. И при отображении одной в другую существуют проблемы, которые нам нужно решить самостоятельно. Давайте их разберем.
Для иллюстрации возьмем следующий пример: у нас есть сущность “Пользователь”, который может быть либо джедаем либо штурмовиком. У джедая обязательно должна быть сила, а у штурмовика специализация. Ниже приведена диаграмма классов.
Проблема 1. Наследование и полиморфные запросы.
В объектной модели есть наследование, а в реляционной нет. Соответственно это и первая проблема — как правильно отобразить наследование в реляционную модель.
Hibernate предлагает 3 варианта ее отображения такой объектной модели:
- Все наследники лежат в одной таблице:
@Inheritance(strategy = InheritanceType. SINGLE_TABLE)

В этом случае, общие поля и поля наследников лежат в одной таблице. Используя такую стратегию мы избегаем join-ов при выборе сущностей. Из минусов стоит отметить, что во-первых, мы не можем в реляционной модели задать “NOT NULL” ограничение для колонки “force” и во-вторых, мы теряем третью нормальную форму. (появляется транзитивная зависимость неключевых атрибутов: force и disc).
На мой взгляд это лучший вариант отображения объектной модели в реляционную.
- Специфичные для сущности поля лежат в отдельной таблице.
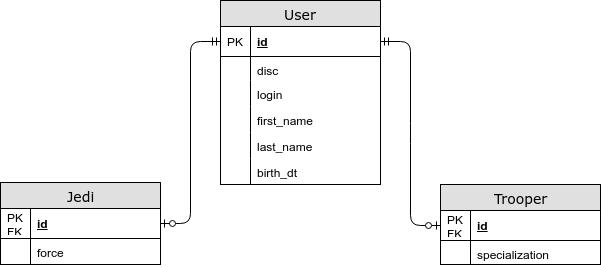
В этом случае общие поля хранятся в общей таблице, а специфичные для дочерних сущностей — в отдельных. Используя эту стратегию у нас появляется JOIN при выборе сущности, но теперь мы сохраняем третью нормальную форму, а также можем указать NOT NULL ограничение в базе данных.
- Для каждой сущности есть своя таблица
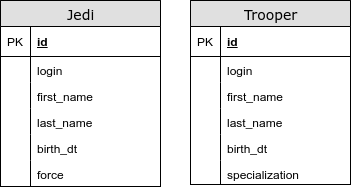
В этом случае у нас нет общей таблицы. Используя эту стратегию, при полиморфных запросах мы используется UNION. У нас появляеются проблемы с генераторами первичных ключей и другими ограничениями целостности. Данный тип отображения наследования строго не рекомендуется использовать.
Проблема 2. Отношение композиции в ООП
Возвращаясь к нашему примеру заметим, что в объектной модели мы вынесли профиль пользователя в отдельную сущность — Profile. Но в реляционной модели мы не стали выделять под нее отдельную таблицу.
Отношение OneToOne чаще является плохой практикой, т.к. в селекте у нас появляется неоправданный JOIN (даже указав fetchType=LAZY в большинстве случаев у нас JOIN останется — эту проблему обсудим позже).
Batching
По-умолчанию запросы отправляются в БД по одному. При включении batching-а hibernate сможет в одном запросе к БД отправлять несколько statement-ов. (т.е. batching сокращает количество round-trip-ов к БД)
Для этого необходимо:
- Включить batching и задать максимальное количество statement-ов:
hibernate.jdbc.batch_size (Рекомендуется от 5 до 30)
- Включить сортировку insert-ов и update-ов:
hibernate.order_inserts
hibernate.order_updates
- Если мы используем версионирование, то нам также нужно включить
hibernate.jdbc.batch_versioned_data — тут будьте аккуратны, нужно чтобы jdbc driver умел отдавать количество строк, затронутых при update-е.
Так же напомню, про эффективность операции em.clear() — она отвязывает сущности от em-а, тем самым вы освобождаете память и сокращаете время на операцию dirty checking.
Если мы используем postgres, то можно так же сказать hibernate использовать multi-raw insert
.
Тестирование
В идеале development окружение должно предоставлять как можно больше полезной информации о работе hibernate и о взаимодействии с БД. А именно:
- Логирование
- org.hibernate. SQL: debug
- org.hibernate.type.descriptor.sql: trace
- Статистика
- hibernate.generate_statistics
Из полезных утилит можно выделить следующее:
- DBUnit
— позволяет описывать состояние БД в XML формате. Иногда бывает удобно. Но лучше еще раз подумайте надо ли оно вам. - DataSource-proxy
- p6spy
— одно из самых старых решений. предлагает расширенное логирование запросов, время выполнения, итд - com.vladmihalcea:db-util:0.0.1
— удобная утилита для поиска N+1 проблем. Также она позволяет логировать запросы. В состав входит интересная аннотация Retry
, которая повторяет попытку выполнить транзакцию в случае OptimisticLockException. - Sniffy
— позволяет сделать assert на количество запросов через аннотацию. В некотором плане изящнее, чем решение от Влада.
- p6spy
Но еще раз повторюсь, что это только для development, на production это включать не стоит.
Entity Manager
Каждый экземпляр EntityManager-а (EM) определяет сеанс взаимодействия с базой данных. В рамках экземпляра EM-а, существует кэш первого уровня. Тут я выделю следующие значимые моменты:
Deadlock
Давайте разберем на примере псевдокода ситуацию, которая может привести к deadlock-у:
Thread #1:
update entity(id = 3)
update entity(id = 2)
update entity(id = 1)
Thread #2:
update entity(id = 1)
update entity(id = 2)
update entity(id = 3)
Для предотвращения таких проблем у hibernate есть механизм, который позволяет избежать deadlock-ов такого типа — параметр hibernate.order_updates. В этом случае все update-ы будут упорядочены по id и выполнены. Также еще раз упомяну, что hibernate старается “отсрочить” захват коннекшена и выполнение insert-ов и update-ов.
Генераторы
Генераторы нужны для описания, каким способом первичные ключи наших сущностей будут получать значения. Давайте быстро пробежимся по вариантам:
- GenerationType. AUTO
— выбор генератора осуществляется на основе диалекта. Не самый лучший вариант, так как тут как раз действует правило “явное лучше неявного”. - GenerationType. IDENTITY
— самый простой способ конфигурирования генератора. Он опирается на auto-increment колонку в таблице. Следовательно, чтобы получить id при persist-е нам нужно сделать insert. Именно поэтому он исключает возможность отложенного persist-а и следовательно batching-а. - GenerationType. SEQUENCE
— наиболее удобный случай, когда id мы получаем из sequence. - GenerationType. TABLE
— в этом случае hibernate эмулирует sequence через дополнительную таблицу. Не самый лучший вариант, т.к. в таком решении hibernate приходится юзать отдельную транзакцию и lock на строчку.
Поговорим немного подробнее про sequence. С целью повысить скорость работы hibernate использует разные алгоритмы-оптимизаторы. Все они нацелены на уменьшение количества общений с БД (количество round-trip-ов). Давайте посмотрим на них чуть подробнее:
- none
— без оптимизаций. за каждым id дергаем sequence. - pooled и pooled-lo
— в этом случае наш сиквенс должен увеличиваться на некий интервал — N в БД(SequenceGenerator.allocationSize). А в приложении у нас появляется некий pool, значения из которого который мы можем присваивать новым сущностям не обращаясь к БД. - hilo
— для генерации ID алгоритм hilo использует 2 числа: hi (хранится в БД — значение, полученное от вызова sequence) и lo(хранится только в приложении — SequenceGenerator.allocationSize). На основе этих чисел интервал для генерации id рассчитывается так: [(hi — 1) * lo + 1, hi * lo + 1). По понятным причинам этот алгоритм считается устарелым и использовать его не рекомендуется.
Теперь давайте разберемся, как выбирается оптимизатор. У hibernate есть несколько генераторов sequence. Нам будет интересно 2 из них:
- SequenceHiLoGenerator
— старый генератор, который использует hilo оптимизатор. Выбирается по-умолчанию, если у нас свойство hibernate.id.new_generator_mappings == false. - SequenceStyleGenerator
— используется по-умолчанию (если свойство hibernate.id.new_generator_mappings == true). Этот генератор поддерживает несколько оптимизаторов, но по-умолчанию используется pooled.
Сила References
Reference — это ссылка на объект, загрузку которого мы решили отложить. В случае отношения ManyToOne с fetchType=LAZY, мы получаем такой reference. Инициализация объекта происходит в момент обращения к полям сущности, за исключением id (т.к. значение этого поля нам известно).
Стоит отметить, что в случае Lazy Loading-а reference всегда ссылается на существующую строку в БД. Именно по этой причине большинство случаев Lazy Loading-а в отношениях OneToOne не работает — hibernate необходимо сделать JOIN для проверки существования связи и JOIN уже был, то hibernate загружает его в объектную модель. Если же мы укажем в OneToOne связи nullable=true, то LazyLoad должен заработать.
Мы можем и самостоятельно создать reference, используя метод em.getReference. Правда в таком случае нет гарантии, что reference ссылается на существующую строку в БД.
Давайте приведем пример использования такой ссылки:
// используем bag
spaceCraft.getCrew().add( em.getReference( User.class, 1L ) ); // весь экипаж не загружается из бд, пользователь тоже не будет загружен
На всякий случай напомню, что мы получим LazyInitializationException в случае закрытого EM-а или отсоединенной(detached) ссылки.




